
Designing AI Agents That Think in Real Time
The System Design Playbook Behind Tavily’s Multi-Agent Future

AI agents are no longer just “cool demos.” They’re in workflows where a wrong answer can cost you money, reputation, or both. The problem? Models trained on static data can’t answer real-time questions like “What’s the score right now?” or “Is the vulnerability patched yet?” Tavily’s bet is that the internet is still the best source for fresh, grounded context, if you can get it into the model quickly and reliably.
🚀 From Side Project to 20K GitHub Stars
Tavily started in 2023 with GPT Researcher, an open source tool that surfed the web, grabbed content, and wrote reports.
20,000+ GitHub stars in < 2 years
Developers wanted better RAG pipelines with real-time search baked in, not just vector search over static data.
This led Tavily toward CRAG (Corrective RAG) patterns—systems that automatically hit the web when local context is insufficient.
📡 The Real-Time Knowledge Gap
Static training data ages quickly. If you’re an AI agent, “close enough” answers don’t cut it. Tavily’s infrastructure ensures agents pull in live, verified data before responding like routing a query for “weather today” to a fresh data source rather than hallucinating from stale embeddings.
Weiss, Tavily’s CEO, frames it like this: “Agents aren’t humans. They don’t care about pretty UIs. They just want the fastest, cleanest answer possible.”
🏎 MongoDB as the Engine
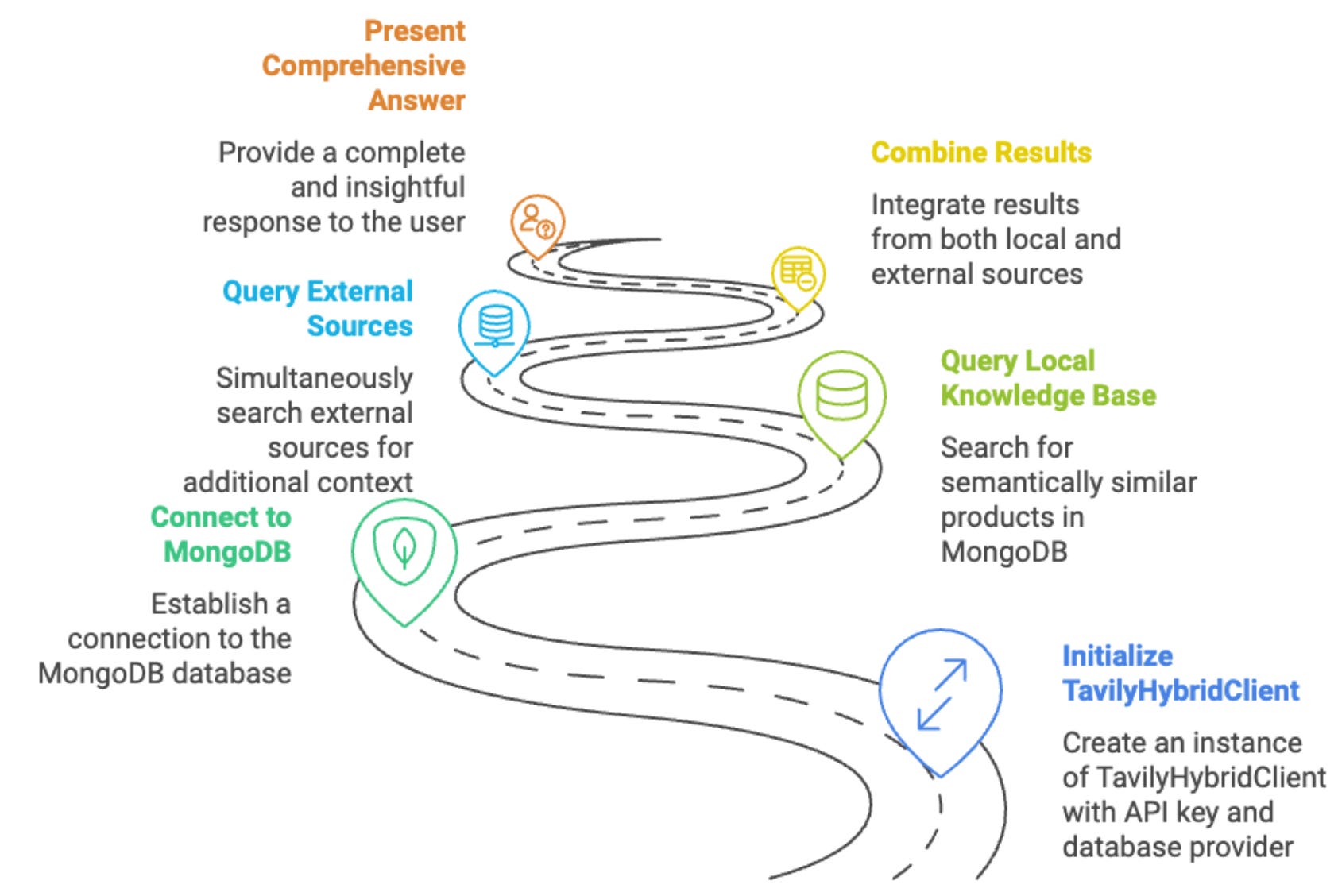
Performance and latency are make-or-break here. Tavily picked MongoDB Atlas for a few key reasons:
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.