
🧠 Dropbox Dash and the Real Work of Business-Ready AI
How RAG and AI agents help meet the needs of businesses

Imagine your company’s sales lead asks, “Can you pull up the latest pitch deck we shared with that logistics prospect in Chicago last quarter?” It’s probably scattered across apps, maybe a Slack thread, maybe a Notion doc, maybe hidden inside Google Drive or buried in a CRM note.
And now you’ve lost 15 minutes playing cloud-file whack-a-mole.
That’s the kind of fragmentation Dropbox Dash was built to fix. The team built a layered system with RAG, AI agents, and a custom-built interpreter—all tuned to the messiness of business workflows.
🔍 The Hard Problem: Enterprise Data Is a Swamp
Dropbox faced three overlapping monsters:
Data Diversity: Emails, PDFs, calendar invites, CRM records, spreadsheets, whiteboard images each with different structure, context, and access patterns. A model needs to interpret structured fields, unstructured text, metadata, and sometimes even embedded objects.
Data Fragmentation: The same concept—"client proposal" or "Q2 results"—might live across six tools. You’ll find references in Slack, raw content in Docs, backups in Dropbox, summaries in Notion, and scheduling references in Calendar. Fragmentation isn't just about access, it's about reconstructing a complete picture from partial signals.
Multimodal Complexity: Business data includes charts embedded in PowerPoints, transcribed audio meetings, image-based scans of PDFs, and mixed-format records like screen recordings with voice commentary. Dash had to parse and reason across formats that span beyond what traditional text search handles.
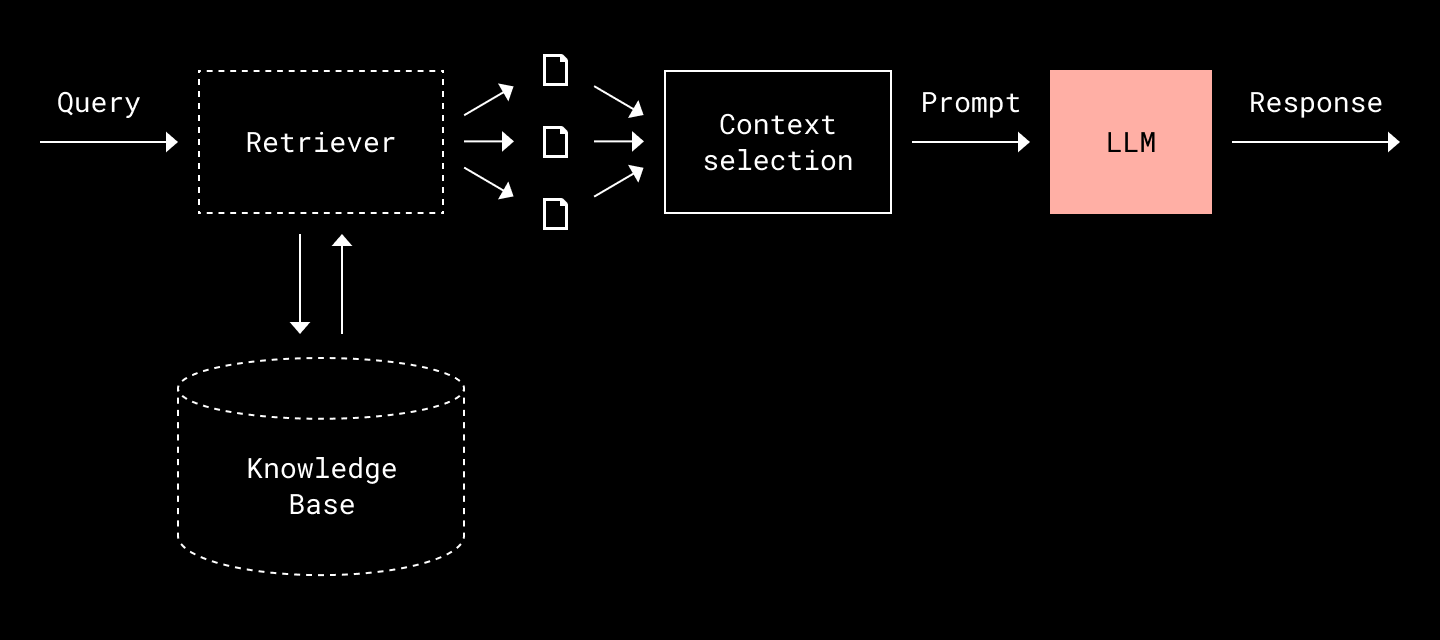
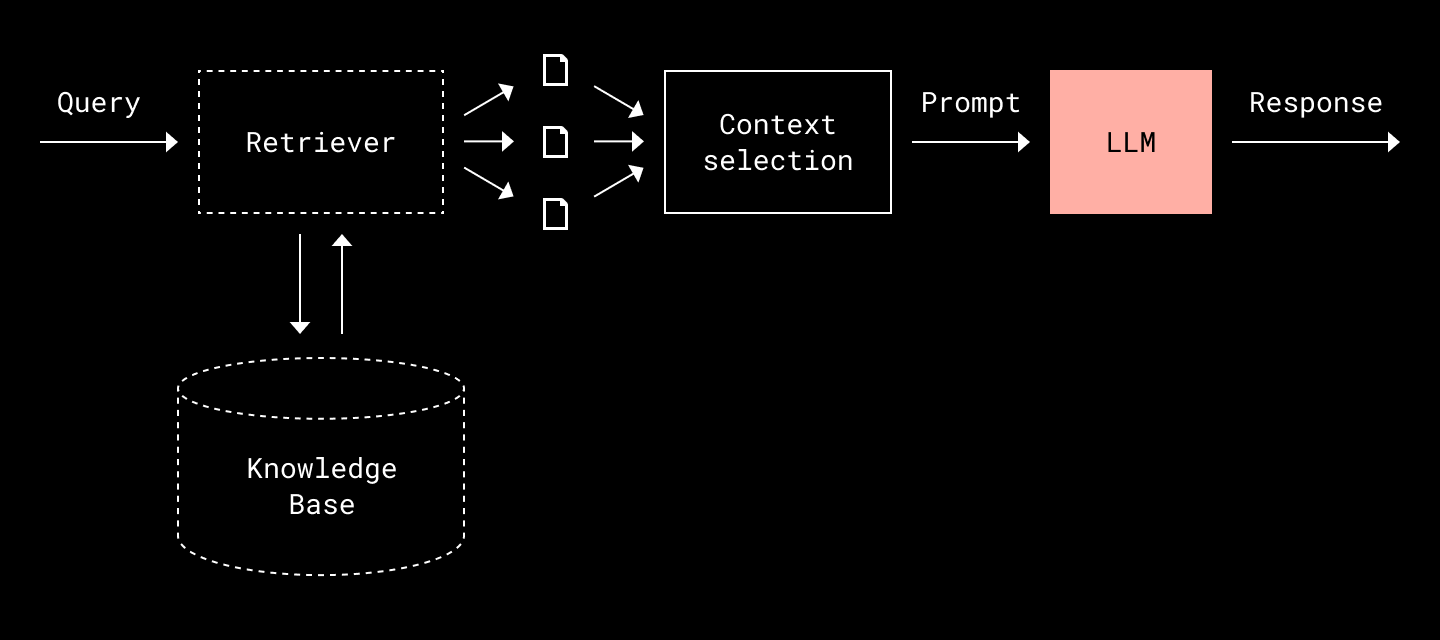
🔗 Retrieval-Augmented Generation: Getting the Right Docs in the Room
To keep results relevant, secure, and fresh, Dropbox leaned on RAG. In short:
Retrieve relevant content from fragmented, multi-modal datasets with context-aware filtering.
Generate answers via an LLM, constrained to the retrieved context.
But pulling this off reliably meant building a robust retrieval layer.
On-the-Fly Chunking: Instead of static pre-processing, Dash slices documents at query time. This ensures up-to-date, context-relevant chunks and avoids bloating indexes with irrelevant segments.
Lexical + Semantic Fusion: First, a fast lexical (term-based) search fetches candidate documents. Then, embeddings rerank based on semantic similarity, enabling smarter ordering without full-vector DB latency.
Freshness via Syncs and Hooks: Dash uses periodic data syncing to keep indexes fresh and webhooks to ingest real-time deltas from connected apps. This supports evolving datasets like calendars or fast-changing CRMs.
Performance Tuning: They targeted 95% of queries under 2s. This dictated lightweight embedding models, aggressive query filtering, and balancing cost vs. quality at every layer.
Evaluation Framework: Dropbox ran tests across open datasets like Natural Questions and MuSiQue, with multiple evaluation layers:
LLM Judges: Used to assess factual correctness and completeness.
Source Recall & Precision: Ensured that retrieved chunks actually contained the necessary info.
Answer F1: Measured overlap with known correct answers.
🤖 AI Agents: Not Just Answers, Actions
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.