
From Flat to Flexible: Rewriting GitHub Issue Search with Nested Elasticsearch Logic
How GitHub Engineered Nested Search with Elasticsearch

Welcome to the 264 new subscribers who joined since the last edition, glad you're here.
This week, we're looking at how GitHub finally brought nested boolean queries to Issues search, a feature devs had been asking for since, well, forever. Sounds like a simple syntax upgrade. In reality, it meant ripping out one of GitHub’s oldest systems and rebuilding it, from parser to query engine to generate complex, recursive Elasticsearch queries without degrading performance across 160 million daily searches.
If you're a senior engineer working with Elasticsearch, this is worth your time. It's a detailed look at how to refactor a legacy system, roll it out safely, and make advanced queries perform well at scale.
TLDR
If you've ever tried searching GitHub Issues with anything more complex than a few filters, you know the frustration. You want something like "all open issues assigned to me that are either bugs or epics," but all you get is silence, or worse, noise.
After nearly a decade of developer requests, GitHub finally shipped a more expressive issue search with real boolean logic, nested parentheses, and full control over how filters combine. This was a surgical replacement of the entire query engine behind one of GitHub’s most heavily used features, processing 160 million queries per day.
The Pain of Flat Queries
Before this update, GitHub’s search syntax was simple, and that was part of the problem. All filters were joined with implicit ANDs. There was no way to say "this OR that" unless you were filtering by label, and even then, only with a comma-separated list.
That limitation blocked many power users. Want to find issues assigned to you that are either type:bug or type:epic? You were out of luck. This lack of expressiveness led developers to kludge together workarounds, often involving external scripts or brittle filter combos.
The community asked again and again, for years. GitHub shipped a partial fix in 2021. But this time, they committed to doing it right, and doing it safely.
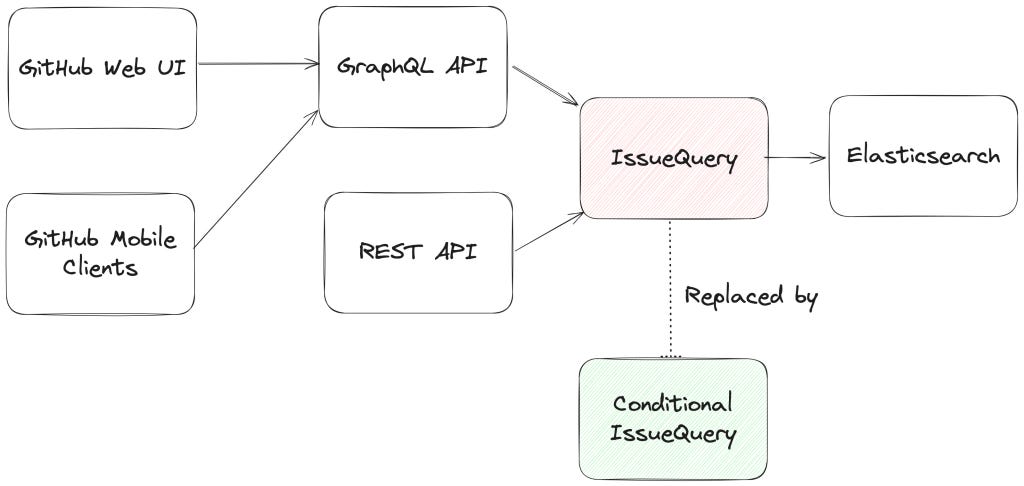
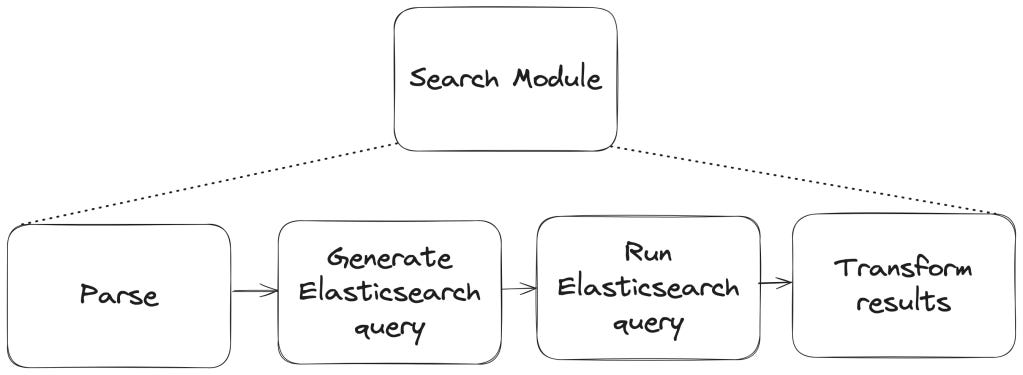
How Search Works (and Why It Had to Change)
Issue search happens in three steps:
Parse: Convert the user’s query string into something the backend can reason about.
Query: Translate that structure into an Elasticsearch query.
Normalize: Map Elasticsearch results to Ruby objects and filter out stale records.
Only steps 1 and 2 needed to change. But that was plenty.
Parsing: From Strings to Syntax Trees
The old parser worked like a grocery list. You’d feed it a search string, and it would split it into filters: label, assignee, text. All flat, no hierarchy.
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.