
GitHub Copilot Uses Your Code for Their APIs
Your code is the real copilot

⚡️TLDR;
GitHub Copilot suggests code based on the coding tabs you have open. It’s context aware but it’s not actually reading your entire code base yet.
🎩 Limits of LLM Magic
LLM means Large Language Model. It basically means there’s machine learning that read a ton of text (or code) and can guess what the next line of text should be.
From the article:
GitHub Copilot can process about 6,000 characters at a time
This means copilot can only read 6000 characters to guess how to auto-complete your code. So it can’t read your entire code base (yet)
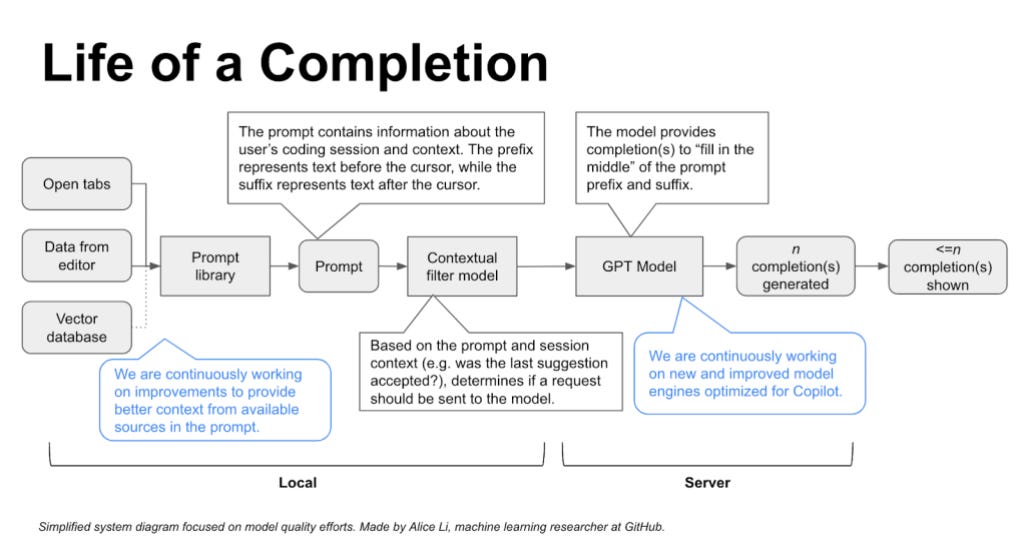
🤔 How does it choose those magical 6,000 characters?
Here’s how a prompt is created:
Algorithms first select relevant code snippets or comments from your current file(s). Other file tabs are included
These snippets and comments are then prioritized, filtered, and assembled into a prompt that asks the LLM to give a coding suggestion
🔧 High bar or low bar for suggestions?
Low-bar. The more people accept a suggestion, the more data the Copilot LLM has on making a better suggestion.
