


How a 3.4 Million Concurrent Users Spike Took Down Fortnite’s Backend
A Deep Dive into Scaling Failures, Database Bottlenecks, and Recovery Strategies

BYE-BYE-BORING (Sponsored By SketchWow)

More dull diagrams in 2025? Nope. We gotchu!
Paste in text or a URL. In 9 seconds, generate dozens of eye-catching visuals (mind maps, animated diagrams, visual summaries, infographics) to communicate your ideas, solutions, process and more.
Give SketchWow a try for 30 days. See what happens!
Use This Link. You'll Save An Extra 10%!
https://sketchwow.com/BYTE10OFF
🚀 TL;DR
On February 3-4, 2018, Fortnite experienced a massive outage, disrupting millions of players worldwide. The root cause? Their backend wasn’t ready for an unexpected surge to 3.4 million concurrent users (CCU), leading to cascading failures across databases, matchmaking, and authentication systems.
Let’s break it down.
Fortnite's backend collapsed under extreme load, exposing key bottlenecks in scaling. The failures included:
✅ MCP Database Overload: Writes queued indefinitely, causing matchmaking delays.
✅ Thread Pool Starvation: A thread misconfiguration throttled database connections.
✅ Memcached Saturation: Authentication failures led to service-wide downtime.
✅ XMPP Failure: Friends and social features became unresponsive.
What We’ll Cover:
1️⃣ 🛠️ What Happened? (The sequence of failures that broke Fortnite’s backend)
2️⃣ 🛑 Root Causes (How scaling limits led to database and service failures)
3️⃣ 🤔 Lessons Learned (How Epic reworked their backend to handle growth)
4️⃣ 🏗️ How to Prevent This in Your Own Systems (Paid)
🔍 Background: How Fortnite’s Backend Was Built
At the time, Fortnite’s backend architecture relied on MongoDB sharding, Memcached caching, and XMPP-based messaging to support its explosive growth. The game’s Matchmaking Control Plane (MCP) handled all matchmaking requests, while Epic’s Account Service managed user authentication.
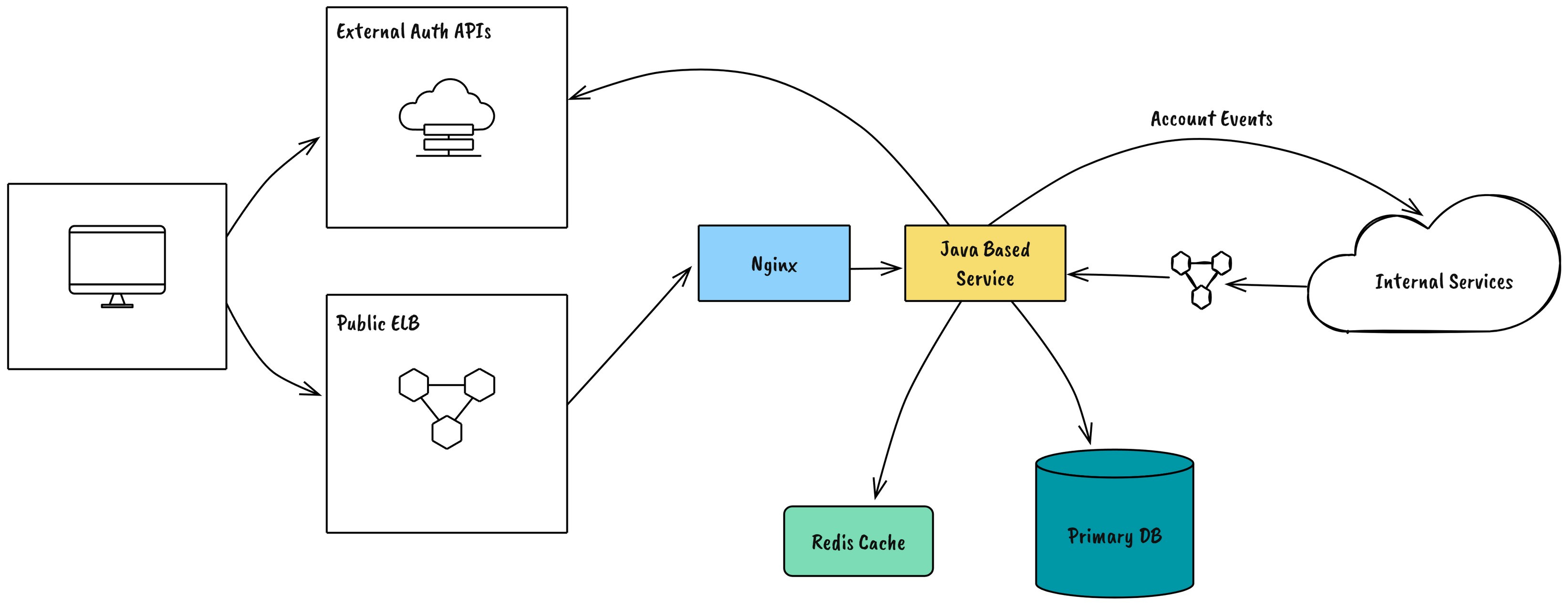
💡 Key Stats:
🔹 124K requests/sec handled by MCP
🔹 318K database reads/sec and 132K writes/sec
🔹 100K authentication requests/sec during peak hours
🔹 3M+ persistent XMPP connections for social features
Fortnite's architecture was designed for high throughput, but rapid growth exposed fundamental scaling issues.
🛠️ What Happened?
It started with a record-breaking CCU peak. Fortnite's infrastructure wasn’t prepared for the sudden jump to 3.4 million players. The result? A chain reaction of failures.
🚨 Matchmaking Bottlenecks:
1️⃣ MCP’s primary database shard couldn’t handle the influx of matchmaking requests. Writes queued up, leading to a 40-second+ delay per operation.
2️⃣ Database threads maxed out, blocking all new matchmaking requests.
3️⃣ Manual failovers were required multiple times per hour to restore service.
🚨 Authentication Failures:
1️⃣ Memcached, used for caching authentication tokens, became overwhelmed.
2️⃣ The authentication proxy (Nginx) exhausted all worker threads, blocking login requests.
3️⃣ Users were forcefully signed out and couldn’t log back in.
🚨 Social Features Went Dark:
1️⃣ XMPP, which powered friends lists, party invites, and chat, started failing.
2️⃣ The Friends Service Load Balancer became overloaded, making everyone appear offline.
3️⃣ This effectively killed all social interactions in Fortnite.
🛑 Root Causes
1️⃣ MongoDB Write Queues Crashed Matchmaking
Matchmaking writes queued indefinitely, waiting for database resources. This led to system-wide blocking.
2️⃣ Thread Misconfiguration Starved the System
A change in MCP’s thread pool configuration reduced available worker threads, creating artificial bottlenecks.
3️⃣ Memcached Saturation Took Down Authentication
The proxy handling authentication timed out waiting for Memcached, blocking all login requests.
4️⃣ XMPP Dependency on a Single Load Balancer
The XMPP service relied on a single load balancer, which became overloaded and failed.
🤔 Lessons Learned
1️⃣ Capacity Planning Must Be Aggressive
If your system is growing exponentially, assume peak load scenarios and pre-scale resources.
2️⃣ Thread Configurations Should Match Production Workloads
Changes that look good in staging can fail catastrophically in production if thread pools aren’t properly tuned.
3️⃣ Authentication Caching Should Be Redundant
Memcached failures shouldn’t bring down logins—multiple caching layers can prevent this.
4️⃣ XMPP Services Need Smarter Load Balancing
Load balancers must be fault-tolerant, and failover processes need to be tested under high load.
5️⃣ Database Performance Requires Continuous Tuning
Identifying and resolving bottlenecks early can prevent cascading failures. Invest in real-time monitoring and auto-scaling solutions.
6️⃣ Optimize Network and Connection Pooling Strategies
Overloading connection pools or failing to tune TCP/IP settings can choke services under extreme load. Proactively test and adjust configurations.
7️⃣ Reduce Blast Radius During Failures
Segment critical services to ensure a single point of failure doesn’t cascade into total downtime.
🏗️ How to Prevent This in Your Own Systems
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.