


How a Script Meant to Delete an App Took Down 775 Atlassian Customers
A Deep Dive into Site Deletions, Recovery Bottlenecks, and Process Failures

🎉 Easter Weekend Deal: 30% Off Byte-Sized Design Premium!
Want to level up your system design skills without drowning in 50-page whitepapers?
Byte-Sized Design Premium breaks down real-world architectures from top tech companies, gives you practical insights, and helps you think like a staff engineer.
🧠 Stay sharp, design better systems, and get access to exclusive case studies and deep dives.
🔓 This weekend only: Get 30% off.
Offer ends Monday, don’t miss it!!!
On April 5, 2022, a routine maintenance script at Atlassian mistakenly deleted 883 customer sites, affecting 775 paying customers. Some were offline for 14 days. The root cause? A simple human error paired with brittle automation, dangerous API design, and missing safeguards.
No data was permanently lost, but the damage was significant. Atlassian had to rebuild cloud infrastructure for hundreds of customers, restore backups manually, and re-establish communications from scratch. It became a crash course in operational resilience at scale.
🚀 TL;DR
Atlassian accidentally deleted 883 production sites during a routine script run. The cascade:
Script used site IDs instead of app IDs
The deletion API didn’t validate input type (site vs app)
There was no soft delete or warning mechanism
Site metadata, user info, and contact details were lost
Recovery tooling didn’t support mass restoration

Here’s what we’ll cover:
What Happened – How 883 sites disappeared in 23 minutes
Root Causes – Where the real failures happened
Lessons Learned – What Atlassian is fixing – (Premium Only)
Recovery – (Premium Only)
🔍 What Happened?
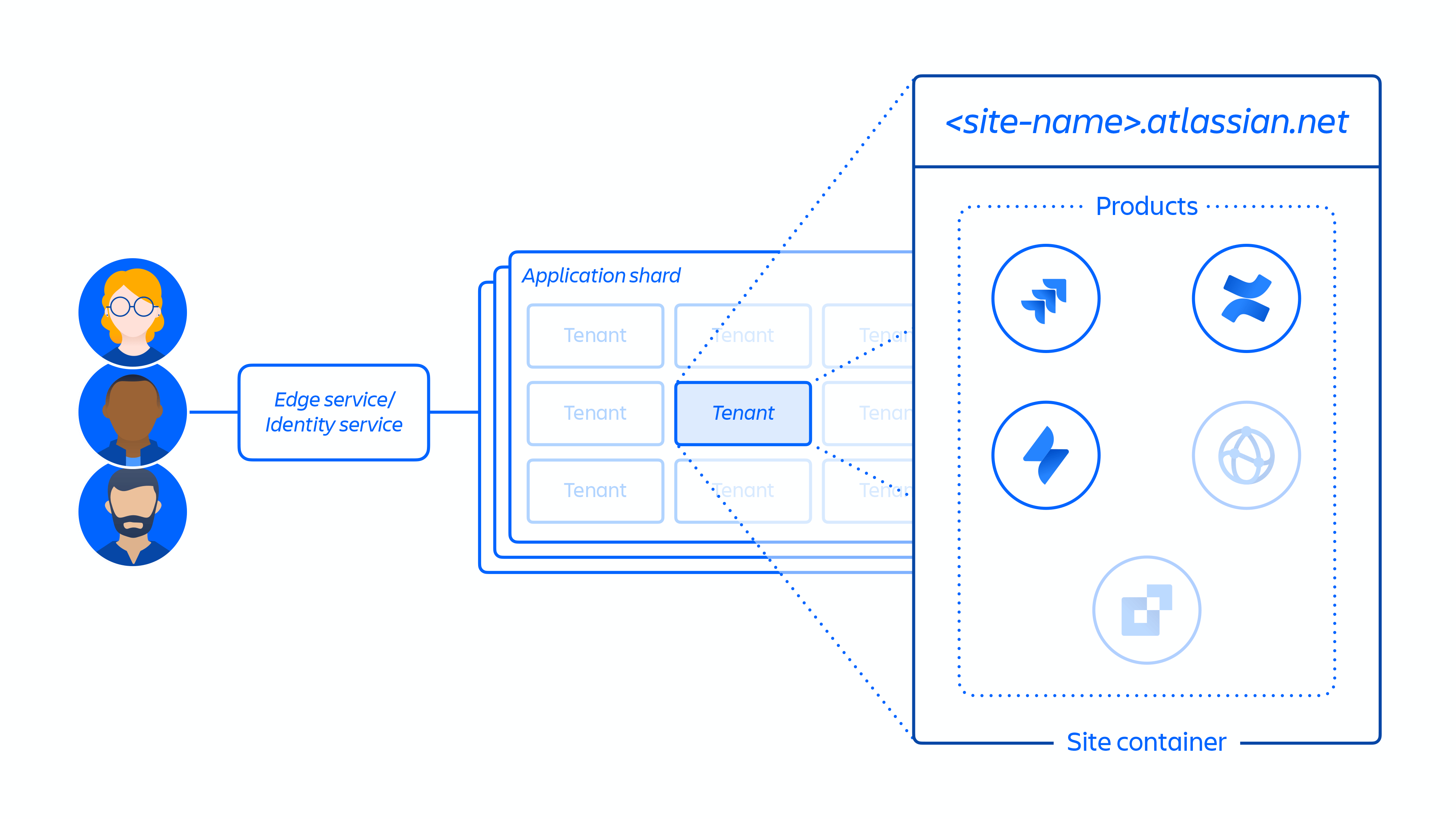
In 2021, Atlassian integrated the Insight app into Jira Service Management. The legacy standalone app had to be deleted from customer sites. A maintenance script was updated to automate this cleanup.
But instead of app IDs, the team running the script accidentally provided site IDs. Worse, the deletion API accepted either value without validating the input type. The result? Entire customer sites all products, users, configs, and metadata, were deleted instantly.
Between 07:38 and 08:01 UTC, 883 sites were deleted. The internal monitoring systems didn’t catch it, because the deletion looked like a legitimate, authorized action.
It wasn’t until 08:17 UTC, when the first customer ticket came in, that Atlassian realized something was wrong. By then, the damage was already done.
Products affected: Jira Software, Jira Service Management, Confluence, Opsgenie, Atlassian Access, and Statuspage.
🚫 Root Causes
1. Dangerous API Behavior
The API for deletion accepted both app and site IDs interchangeably and executed immediately. There were no confirmation steps, guardrails, or human-friendly warnings.
2. No Soft Delete Model
Site deletions were hard and irreversible. There was no grace period, retention buffer, or approval workflow. Once executed, everything was gone.
3. Review Process Missed the Payload Risk
The script passed peer review, but no one checked the actual input IDs. Testing in staging passed because the invalid IDs weren’t present there.
4. Metadata and Contacts Were Also Deleted
When a site was deleted, Atlassian lost access to the customer’s System Admin contacts. Customers couldn’t reach support through normal channels, and Atlassian couldn’t reach them either.
5. DR Systems Weren’t Built for Mass Site Recovery
Atlassian had playbooks for restoring a single site or recovering from infrastructure-level issues. But they had never rehearsed restoring hundreds of multi-product tenant containers at once.
🤨 Lessons Learned
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.