
How Discord indexes Trillions of messages without falling apart

TL;DR
Discord’s 2017 search architecture worked beautifully for billions of messages. By 2025, under the weight of trillions, it collapsed. Redis queues dropped messages. Single node failures cascaded into 40% of bulk operations failing. 200+ node clusters became unmanageable. Guilds hit Lucene’s 2 billion message hard limit with no escape.
The fix? Rethink everything. Smaller clusters grouped into “cells.” Smarter message batching by destination. Kubernetes for orchestration. PubSub for guaranteed delivery. And a migration system that could reindex billions of messages without downtime.
🚨 The Breaking Points
Redis Queues Couldn’t Handle Backpressure
When Elasticsearch nodes failed (which happened often), the indexing queue backed up. Redis CPU maxed out. Messages got dropped. Search became incomplete.
Bulk Indexing Was a House of Cards
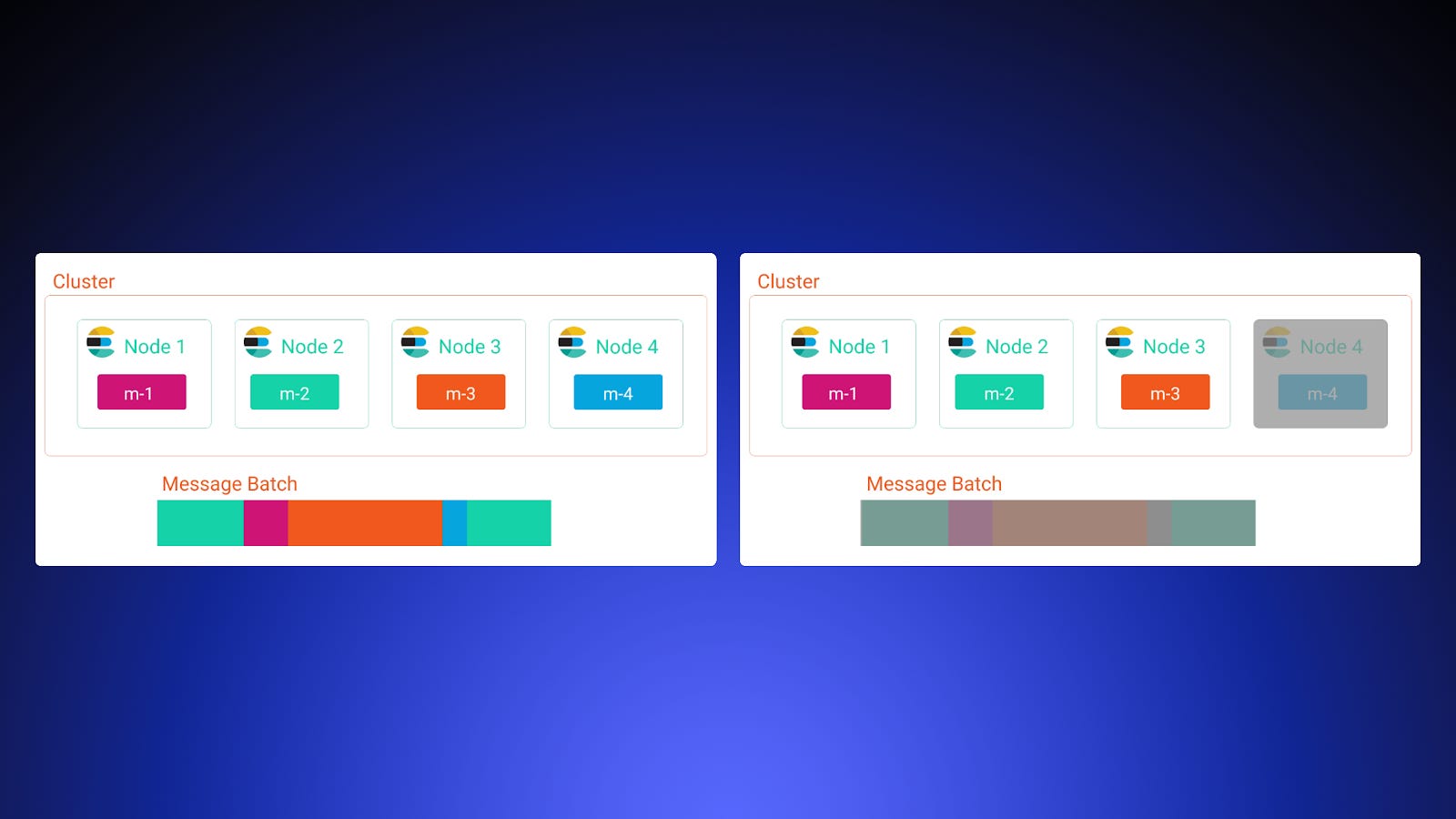
Workers pulled 50-message batches off the queue. Those messages scattered across 50 different Elasticsearch nodes. One node down? ~40% of bulk operations failed. The entire batch re-queued. Rinse and repeat.
Large Clusters = High Coordination Tax
As message volume grew, Discord added nodes. Clusters ballooned to 200+ nodes. But more nodes meant:
Higher coordination overhead
More frequent failures (any node can fail at any time)
Master nodes OOMing from cluster state management
No safe path for rolling restarts or upgrades
The log4shell vulnerability forced them to take search fully offline just to restart nodes with patched configs.
The Lucene MAX_DOC Ceiling
Each Elasticsearch index is a Lucene index under the hood. Lucene caps at ~2 billion documents per index. Large guilds hit this limit. All indexing operations failed. The only fix? Delete spam guilds and hope legitimate communities stayed under the limit.
🔍 Root Causes
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.