
How Disney's Hotstar Scales for 19 million concurrent users
Sometime smaller change can lead to big impact



💰 HELP WANTED
This newsletter has grown to 20,500 → 21,501+ AMAZING READERS. It’s grown to a scale that a single person can’t maintain all of it on their own.
If you’re interested in being a byte-sized design writer, apply here!
tldr:
Problem: Hotstar has discovered needed to scale 19 million concurrent users to be available and consistent for their payment systems. Additional analysis have demonstrated that it was unable to scale to required TPS.
Solution: Updating a single feature produced the intended outcome after a thorough investigation into third-party services.
Flow

Payment Service:
Java Spring Boot app routes transactions,
Aurora MySQL manages states (single writer, multiple readers).
Worker Tasks: Workers handle reconciliation with gateways and relay async payment notifications.
Data Management: MySQL data replicated to data lake via Debezium-Kafka CDC
Kafka queues power payment notifications.
Root causing why Hotstar couldn’t handle 19 millions concurrent users
Ideas that didn’t work
Increasing pod count failed to enhance performance.
Nothing wrong with CPU and Memory usage.
Switching between AWS instance types had no performance improvements in Aurora MySQL.
Real bottleneck - The database was the primary bottleneck because it didn’t have horizontal scaling and also had IO issues.
Investigating the bottleneck
Things that didn’t work
MySQL process list dump revealed no lingering queries impacting performance.
Indexed queries re-evaluated against production database for optimization.
Database connection pool tuning yielded no noticeable performance improvement.
The 19 million bottleneck
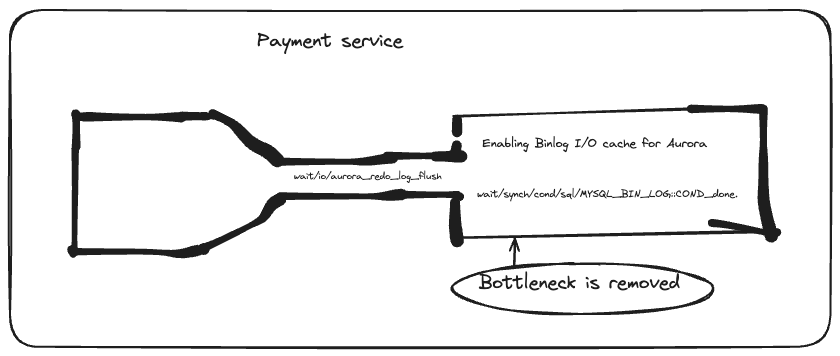
In Aurora MySQL's Performance Insights (PI), two significant wait conditions are monitored:
wait/io/aurora_redo_log_flush: Indicates delays in flushing the redo log, impacting data durability due to small log buffer size or high commit rates.
wait/synch/cond/sql/MYSQL_BIN_LOG::COND_done: Signals contention for the binlog mutex, caused by excessive commit throughput or numerous binlog readers. Disabling the binlog resolved contention, enhancing scalability during load tests.

Real root cause
Resultant wait events like 'wait/io/aurora_redo_log_flush' and 'wait/synch/cond/sql/MYSQL_BIN_LOG::COND_done' come from high commit throughput and its flushing and synchronization processes.
So what can be done?
Just remove the bottleneck. But there’s 2 options we can consider.
Option 1: There are methods to reduce commit throughput, such as turning off auto-commit, using transactions for multiple DML queries, or batching DML statements, but these may necessitate substantial codebase changes and testing efforts due to potential behavioral alterations.
Option 2: Introduce binlog I/O caching in Aurora MySQL 2.10 onwards to resolve synchronization contention. This offers database performance nearly identical to that without active binlog replication.
Survey says: Option 2
Use binlog I/O cache feature in Aurora
Winning Results
Database costs reduced by half by migrating to a smaller instance throughout the tournament.
~30% uptick in TPS (Fig 5. 19.31–19.40 vs 19.55–20.10 ).
🗞️ Official Article and References
Link to the official in depth article:
(Subscribing is the best way to support this newsletter)
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.
 | A guest post by
|