
⚡ How Pinterest Runs Spark at Scale with Moka
How Pinterest rebuilt its massive Hadoop system into a faster, cheaper, and container-native Spark platform.

Pinterest’s old data platform was called Monarch. It ran on Hadoop. It powered everything from ad analytics to recommendation training.
But over time, Hadoop became a drag. Deployments were slow. Maintenance was messy. And scaling meant provisioning giant clusters that ran 24/7, even when idle.
So the Big Data Platform team decided to start fresh.
Their goal: build a Kubernetes-based Spark platform that runs faster, costs less, and gives engineers more control.
They called it Moka. ☕
🚀 Why change at all?
By 2022, Pinterest’s data workloads had outgrown Hadoop’s limits. The team had a checklist for what the next platform should do:
Run inside containers for better isolation and security.
Support Graviton (ARM) for cheaper compute.
Autoscale with Kubernetes instead of fixed-size clusters.
Support modern JDKs (Java 11 +).
Lower operational overhead.
Running Hadoop 2.x on newer EC2 instances was painful. Upgrading clusters meant hours of downtime. And keeping security configurations consistent across hundreds of nodes was nearly impossible.
Kubernetes solved many of these problems — but it wasn’t built for batch data processing. So Pinterest had to rebuild key pieces of the Hadoop ecosystem on top of it.
🧩 How Moka fits together
Moka isn’t just Spark running on Kubernetes. It’s an ecosystem of custom components built to work together.
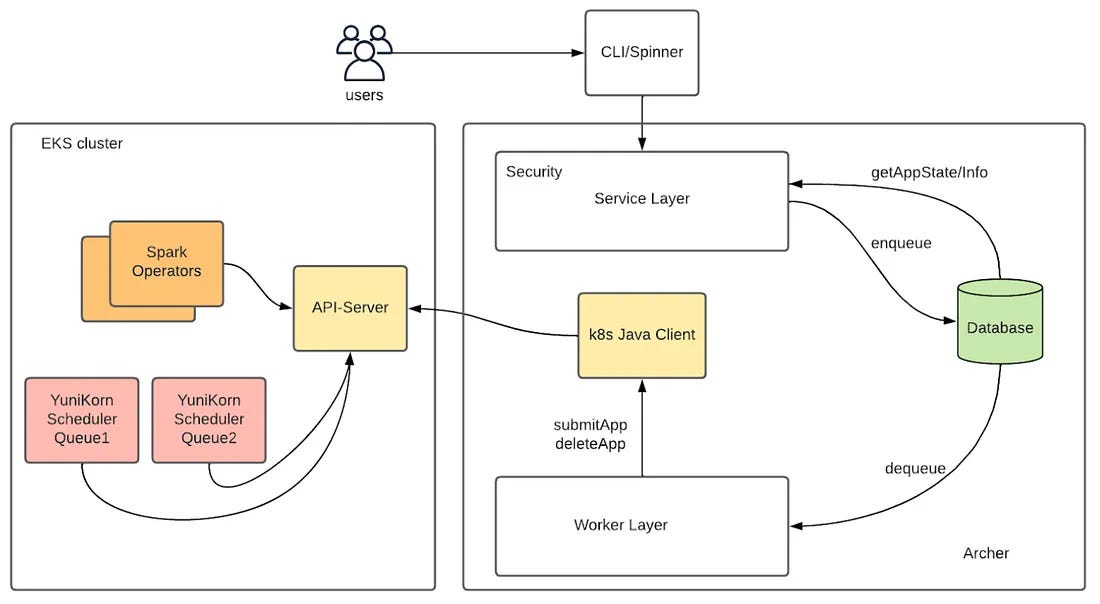
🧠 Archer (Job Submission Service)
Archer replaced Hadoop’s old submission tool (Argonath). It takes jobs from Spinner — Pinterest’s Airflow-based workflow manager — and converts them into Kubernetes Custom Resource Definitions (CRDs).
It tracks job states, retries failed runs, and stores metadata in a database.
⚙️ Spark Operator
Instead of calling spark-submit directly, Pinterest uses Spark Operator. It manages Spark applications in Kubernetes clusters, ensuring drivers and executors are started, monitored, and cleaned up safely.
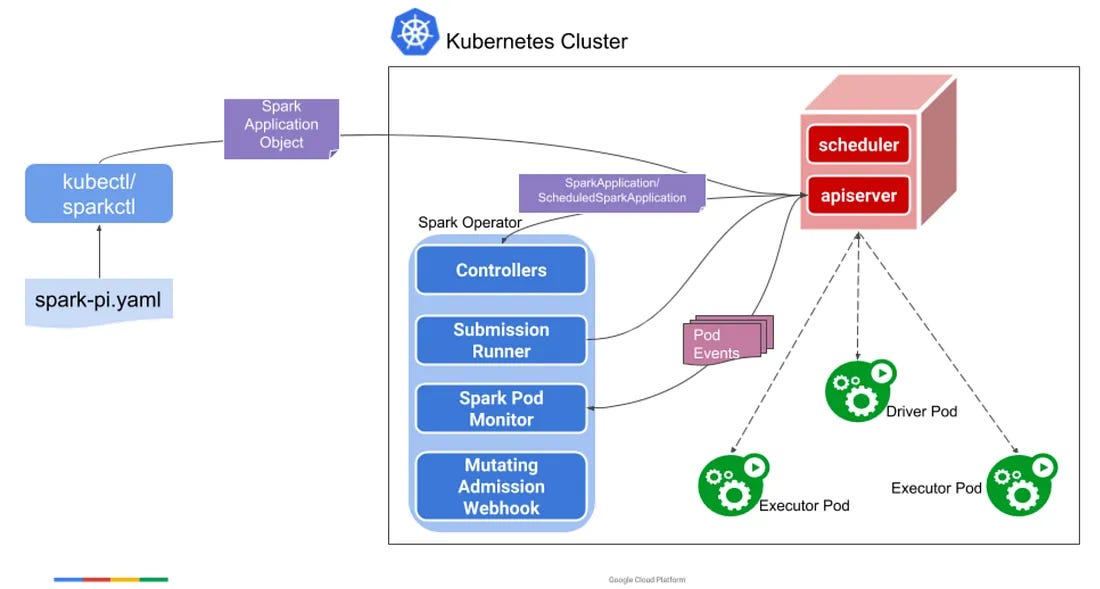
🎯 Fixing Operator bottlenecks
At scale (12,000 + pods), Pinterest ran into issues, driver pods were being garbage-collected before statuses were updated. The fix was to use pod finalizers, which prevent cleanup until job status is saved.
They also ditched admission webhooks (too slow) for pod templates, cutting latency and simplifying deployment.
📊 YuniKorn (Scheduler)
YuniKorn replaced Hadoop’s YARN. It supports queue-based scheduling and preemption, so higher-priority jobs can reclaim resources.
Example: Tier 1 ad-revenue jobs always get space, even if lower-priority batch jobs have to pause.
🔁 Celeborn (Remote Shuffle Service)
Spark’s shuffle is often its slowest part. On Hadoop, they used an external shuffle service (ESS) that caused timeouts and disk contention.
Celeborn decouples shuffle storage from compute, making it faster, more reliable, and enabling dynamic executor scaling. Average job speed improved about 5 %.
📺 Moka UI
A single dashboard for job visibility, engineers can see running jobs, logs, and history without SSHing into nodes or hunting through S3.
🧪 Migrating without chaos
Migrating thousands of production jobs is risky. Pinterest built a dry-run validation system to make it safe.
When a Hadoop job runs in production, Archer automatically runs the same job in Moka’s staging environment. The system swaps production output paths for test buckets.
Once both jobs finish, Archer compares:
file sizes
record counts
checksums
If everything matches, the job is approved for migration.
This automation let the team catch hidden compatibility issues — like small differences in JDK behavior or Spark settings — long before they hit production.
They also recompiled native libraries for ARM64, tuned JVM parameters for Java 11, and rebuilt container images to mirror Hadoop environments as closely as possible.
⚖️ Smarter resource management
Pinterest collects detailed usage data from every workflow. Moka uses that history to decide which queue or cluster a job should run in.
Archer checks this “resource DB” before submission, ensuring high-throughput jobs go to optimized clusters and smaller ones don’t block big ones.
Pinterest also uses temporal autoscaling at night, when internal traffic drops, Moka scales up to use spare compute. During peak hours, it scales down automatically.
📈 What they learned
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.