
🤖 How Salesforce Cut Model Onboarding Time By 75%
Revolutionizing Generative AI Deployment at Scale

The Salesforce Model Serving team is leading the charge in harnessing the power of generative AI. This team has seamlessly integrated Amazon Bedrock CMI, a game-changing platform that simplifies infrastructure and accelerates model deployment. Discover how they tackled long GPU onboarding delays, seamlessly integrated Bedrock without disrupting existing systems, and addressed critical reliability and security issues all while boosting developer productivity.
TLDR
The Model Serving team's mission is to abstract infrastructure complexity and support a diverse array of model types, including large language models (LLMs), multimodal, speech, and computer vision models.
Bedrock CMI has reduced model onboarding time from 6-8 weeks to just 1-2 weeks, a 75% reduction, and significantly improved developer velocity.
Integrating Bedrock CMI into the existing stack required meticulous planning to ensure backward compatibility and prevent disruptions to existing prediction workflows.
The team addressed reliability, observability, and security gaps to trust Bedrock in production, including implementing scoped, temporary access for pulling model weights and metadata.
AI-powered tools like Cursor have further enhanced engineering efficiency, with a 50% reduction in latency and a 4x improvement in throughput for models like ApexGuru.
Why This Matters
The rise of generative AI has transformed priorities for the Model Serving team, leading to an increased demand for rapid iteration, lower latency, and higher standards for reliability and observability. By seamlessly integrating Bedrock CMI, the team has tackled these challenges head-on, revolutionizing the way Salesforce deploys and manages generative AI models at scale.
Overcoming GPU Onboarding Delays
Prior to adopting Bedrock CMI, the process of onboarding models into production was a lengthy and cumbersome affair, often stretching over several weeks. Infrastructure bottlenecks and organizational inefficiencies were major hurdles, with the availability of GPU instances, especially for high-demand models like A100s and H100s, being a critical issue. Securing the required capacity involved extensive planning cycles, with input from various stakeholders, resulting in expensive over-provisioning and underutilized resources.
Streamlining Model Onboarding with Bedrock CMI
Bedrock CMI has streamlined the model onboarding process by eliminating infrastructure friction. As a fully managed, serverless platform, Bedrock removes the need to provision or tune GPU instances, reducing manual steps and speeding up production deployment. This has cut onboarding time from 6-8 weeks to just 1-2 weeks – a 75% reduction – and significantly improved developer velocity, allowing internal teams to test models earlier, discard underperforming ideas quickly, and integrate AI-powered features with minimal delay.
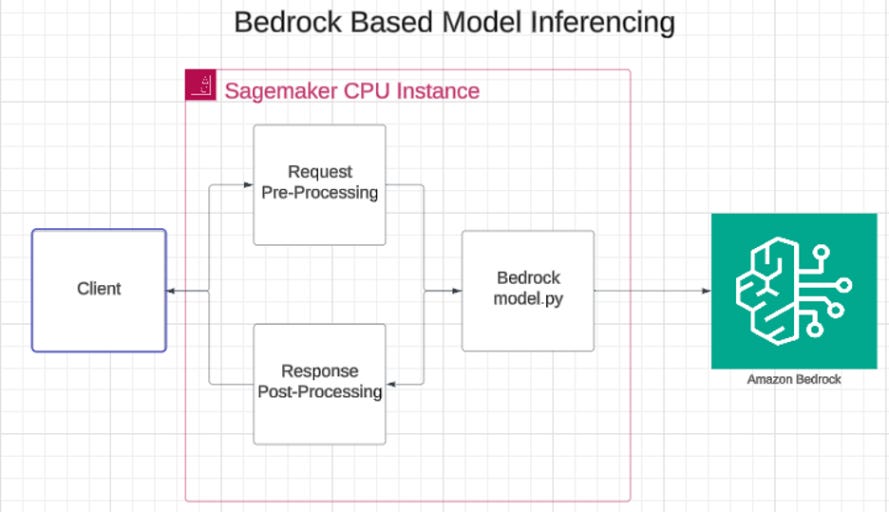
Preserving Architectural Stability
Integrating Bedrock CMI into the existing model serving architecture required meticulous planning to ensure backward compatibility and prevent disruptions to existing prediction workflows. To meet this requirement, SageMaker was configured as a thin pre/post-processing layer that forwards requests to Bedrock. This approach allowed internal product teams to seamlessly access models, regardless of whether they were hosted on SageMaker or Bedrock.
Addressing Reliability, Observability, and Security Concerns
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.