
How Salesforce Migrated 7 Years of Legacy in 4 Months Instead of 2 Years

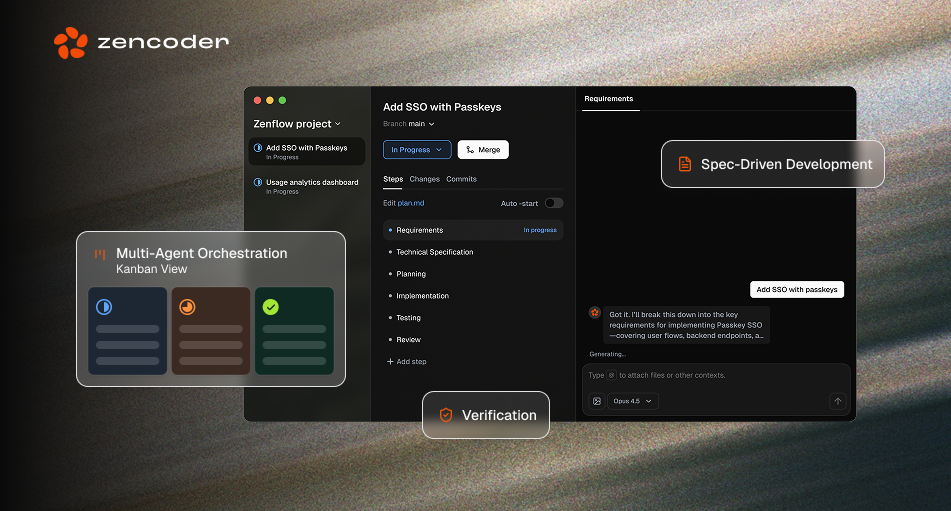
Build Apps with Parallel Coding Agents With One Prompt
Imagine shipping backend services, UI components, refactors, tests, and full features — all from a single prompt, without manually writing specs, breaking down tasks, or stitching AI outputs together.
That’s the power of Zenflow (by Zencoder), a new way of building software with spec-driven AI workflows and parallel coding agents.
With Zenflow you get:
🧩 Spec-Driven Development (SDD)
Agents plan, gather requirements and build specs, always being anchored to evolving specs instead of random chats. They follow the same discipline your best engineers use.
🤝 Multi-Agent Verification
Agents cross-check each other’s work so you don’t have to. Drift and slop get caught before they ever reach you.
⚡ Parallelization at Scale
One engineer. A fleet of agents. Workflows that turn weeks into hours.
🖥️ AI-First UX
Kanban, tasks, subtasks, inbox - finally a UI built for managing AI work at scale.
🔄 Auto-Generated Task Flows
We break work into steps automatically. Less AI babysitting. More shipping.
🎯 Model Diversity
Different AI models challenge each other’s assumptions and catch blind spots.
Better accuracy, fewer surprises
Stop gambling with prompts. Start orchestrating.
GET STARTED FOR FREE
Salesforce’s Own Archive ran fine as a third-party managed package. By 2024, enterprise customers demanded native platform integration because compliance teams won’t sign off on external packages managing core archival data.
The problem? Seven years of undocumented Apex with static methods everywhere. Thousands of tightly coupled files. Deep dependency chains that made file-by-file translation impossible. And multi-tenant Core infrastructure that would choke on single-tenant static designs.
The fix? Dependency graph analysis to identify migration order. Leaf-to-root refactoring that built stable foundations first. Automated transformation with human-validated architectural patterns. And service-layer redesign that turned static spaghetti into scalable Java without breaking production.
🚨 The Breaking Points
Manual Migration Math Didn’t Work
Initial estimates: 2 years. The team had 275 Apex classes, 3,537 total files, and zero documentation on what half of them did. Engineers would need to:
Read every file to understand business logic
Manually rewrite Apex patterns into Java equivalents
Refactor static methods into multi-tenant service layers
Test each change against production behavior
Even small migrations took months. Scale that to thousands of interdependent files? The calendar said 2027 before customers saw value.
Dependency Hell Made Isolated Translation Impossible
You can’t just convert PaymentProcessor.apex to PaymentProcessor.java and call it done. That file calls UtilityHelpers, which references SharedConstants, which imports LegacyDataMapper. Convert one in isolation and you get:
Incomplete method signatures (where’s that utility method?)
Ambiguous return types (what does this constant actually mean?)
Code that compiles but behaves wrong at runtime
Translation order mattered. The system didn’t have one.
Static Methods Killed Multi-Tenancy
The managed package loved static classes and global shared state. Worked great when Customer A’s instance ran separately from Customer B’s. Breaks catastrophically in Core’s shared infrastructure where 50 customers hit the same code simultaneously.
Direct syntax conversion would reproduce single-tenant assumptions. Memory leaks. Isolation violations. Performance collapse under load. The architecture needed fundamental redesign, not just language translation.
🔍 Root Causes
1. Package-First Design Assumed Isolation
Seven years of development optimized for standalone deployment. Every architectural decision—static methods, global state, tight coupling—made sense in that context. Moving to shared multi-tenant infrastructure meant those same decisions became liabilities.
2. No Documentation, No Dependency Map
Legacy code accumulates logic faster than teams document it. Files referenced each other through years of incremental changes. Nobody had a complete picture of what depended on what. Manual analysis would take months before migration even started.
3. Manual Effort Doesn’t Scale to Thousands of Files
Rewriting code file-by-file works for small projects. At scale, it’s a coordination nightmare. Engineers step on each other. Changes ripple unpredictably. Regression risk compounds. The process itself becomes the bottleneck.
🧠 The Solution Architecture
1. Dependency Graph Analysis Revealed Migration Order
First step: Generate a complete dependency graph of the entire codebase. Map every class relationship. Identify which files depend on which.
This revealed natural layers:
Leaf nodes: Constants, utilities, helpers—no dependencies
Mid-level: Business logic that calls leaf nodes
Root nodes: Workflows that orchestrate everything
Migration order emerged automatically: Convert leaves first, then build upward.
The Cold Start Problem: You still need to understand what each file does. Solution: Start with the simplest leaf nodes (constants, basic utilities) that have obvious behavior. Use those as reference implementations when converting more complex files up the chain.
Result: Stable foundation. Each layer referenced only verified code from below. No guesswork about what upstream dependencies should look like.
2. Automated Transformation with Pattern-Based Rules
Defined transformation rules that encoded Core’s architectural patterns:
Convert static methods to service-layer classes
Replace global state with dependency injection
Separate concerns into clear object-oriented boundaries
Engineers reviewed output at each layer, adjusting rules as deeper refactoring needs surfaced. Not “let the machine write code unsupervised”—but “automate the mechanical translation, validate the architectural decisions.”
Critical constraint: Every generated file must compile and pass basic linting before moving to the next layer. Cascading errors break the pipeline.
3. Test Suite Redesign Instead of Direct Migration
Directly migrating Apex unit tests would reproduce legacy assumptions. Instead:
Extract logical intent from each test
Rewrite test suites in Java against new service boundaries
Validate behavior, not implementation details
Example: Old test checked that StaticProcessor.calculate() returned 42. New test validates that the payment service produces correct amounts regardless of implementation approach.
Result: Tests that verify the system works, not that it works the same way.
4. Layered Validation Beyond Automation
Code generation got the team 80% there. The remaining 20% required:
Manual end-to-end flow testing
Bug bash sessions with engineers outside the core team
Early deployment cycles that surfaced integration issues
Planned Selenium automation for UI regression coverage
Early cycles found many issues. Later phases found only a few. The release stabilized through systematic validation, not hope.
🧰 The Cascade of Benefits
Before: Manual file-by-file → 2 years → huge regression risk → blocked on engineer availability
After: Dependency-driven automation → 4 months → layered validation → same team manages 2x the code
Unlocked outcomes:
Native platform integration (compliance teams happy)
Unified deployment pipelines (security scanning built-in)
Consistent architectural patterns (easier to maintain)
Doubled codebase managed by same headcount (support both versions during transition)
🤔 Lessons Learned
1. Dependency Order Is Migration Strategy
You can’t translate interdependent code in random order. Graph analysis isa must have. Leaf-to-root migration prevents cascading errors and provides stable reference implementations at each layer.
2. Automation Requires Architectural Constraints
Pattern-based transformation only works when you define clear target patterns. “Convert this Apex to Java” is too vague. “Convert static methods to service classes with dependency injection following these specific conventions” gives automation something to execute.
3. Tests Validate Intent, Not Implementation
Migrating legacy tests 1:1 preserves old assumptions. Rewriting tests against new boundaries validates that the system solves the same problems, even if implementation differs. This catches architectural mismatches automation can’t see.
4. Scale Changes What’s Possible
Manual migration works for 10 files. Breaks at 100. Completely infeasible at 3,537. The volume itself forced process innovation—dependency graphs, automated transformation, layered validation. Sometimes constraints drive better solutions than greenfield freedom.
5. Human Validation Remains Non-Negotiable
Automated translation accelerated development. But functional correctness required systematic testing, manual review, and iterative refinement. Code that compiles isn’t code that works. Speed without validation just ships bugs faster.
🏗️ What Salesforce Built to Make This Work
Dependency graph generator for entire managed package
Leaf-to-root migration pipeline based on reference direction
Pattern-based transformation rules for Apex-to-Java conversion
Service-layer architecture with dependency injection
Test suite redesign focused on behavioral validation
Multi-phase bug bash process with cross-team participation
Infrastructure to maintain 14,000 files (legacy + new) simultaneously
🏁 Bottom Line
Salesforce didn’t migrate Own Archive because the old version was broken. They migrated because enterprise customers demand native platform integration, and compliance teams won’t approve external packages for core data flows.
For engineering leaders and architects:
Map dependencies before migration starts. You can’t translate interdependent code in arbitrary order. Graph analysis reveals natural layers and eliminates guesswork.
Automate mechanical translation, validate architectural decisions. Pattern-based rules scale to thousands of files. Human review ensures output matches target patterns. Don’t automate blindly—automate strategically.
Redesign tests around new boundaries. Legacy test suites encode legacy assumptions. Rewrite for behavioral validation, not implementation preservation.
Accept that scale breaks manual processes. 10 files? Manual works. 3,537 files? Manual is a 2-year disaster. Volume forces innovation.
Validation is where correctness lives. Fast code generation means nothing if it ships broken behavior. Systematic testing, bug bashes, and iterative refinement are non-negotiable.
Plan for dual-system maintenance. Migration isn’t flipping a switch. The team maintained both versions simultaneously, 14,000 files managed by the same engineers. Plan capacity accordingly.
Legacy migration isn’t about rewriting old code. It’s about extracting value from proven systems while aligning with modern architectural constraints. Salesforce built a process where “modern” arrived in 4 months, not 2 years.
Brilliant case study on how dependency mapping changes migratoin economics. The leaf-to-root ordering basically turns an N-squared coordination problem into something actually managable. I've seen similar patterns in microservice decomposition where teams tryto carve services arbitrarily and end up with circular deps everywhere. One thing I'd add is that the "80% automation, 20% human validation" split probably varies a lot based on how much domain logic is embedded in those static methods vs just being plumbing code.