


How Slack Cut Frontend Build Times by 60%
A Case Study in DevXP, CI/CD Optimization, and Developer Joy

🎉Last Day to Grab the Easter Deal: 30% Off Byte-Sized Design Premium!
Byte-Sized Design Premium breaks down real-world architectures from top tech companies, gives you practical insights, and helps you think like a staff engineer.
🧠 Stay sharp, design better systems, and get access to exclusive case studies and deep dives.
Offer ends Today, don’t miss it!!!
In large engineering orgs speed to deploy can be the difference between flow and frustration. At Slack, the DevXP team spotted a subtle but costly inefficiency in their CI/CD pipeline: frontend builds were running even when no frontend code had changed.
The result? Wasted compute, slower merges, and gigabytes of redundant data clogging up AWS S3.
Let’s break down how they turned this silent productivity killer into a 60% efficiency gain without writing any brand-new tools.
🚀 TL;DR
Slack engineers optimized their E2E testing pipeline by skipping unnecessary frontend builds. They used git diff to detect relevant code changes, reused recent assets via an internal CDN, and cut build frequency by 60% saving time, compute, and terabytes of cloud storage.
Here’s what we’ll cover:
What Happened
The Fix - Don’t Build What You Don’t Need
What Made This Hard?
The Results
Lessons For Devops and infra teams
1️⃣ 🛠️ What Happened?
Slack’s main monorepo runs full end-to-end tests before merging any code. This covers everything from backend logic to the frontend UI. But there was a catch:
Every PR triggered a full frontend build. Even if the changes were in backend-only files.
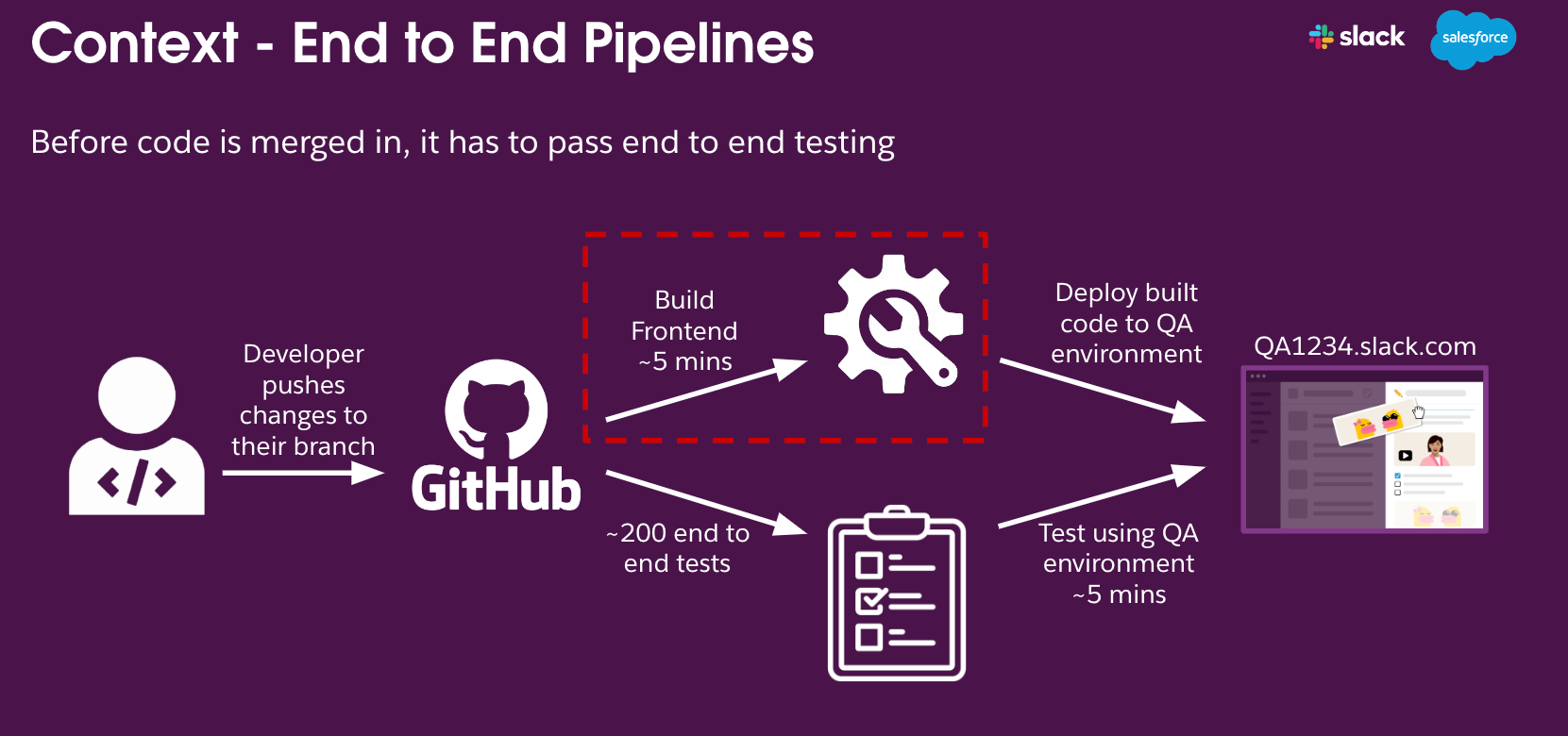
🕐 Each frontend build took ~5 minutes
📦 Each artifact was nearly 1GB
📈 Multiply that by hundreds of PRs per day
You get:
❌ Redundant builds
❌ Slower pipelines
❌ Expensive cloud usage
2️⃣ 🧠 The Fix: Don’t Build What You Don’t Need
Instead of overhauling their system, Slack made two smart tweaks:
Step 1: Check Before You Build
They used git diff to detect whether a PR touched any frontend files. If not, the pipeline skipped the build.
Step 2: Reuse What You Already Have
They fetched a recent, still-in-production build from AWS S3 and served it via an internal CDN. This meant:
No new build
No storage bloat
No time wasted
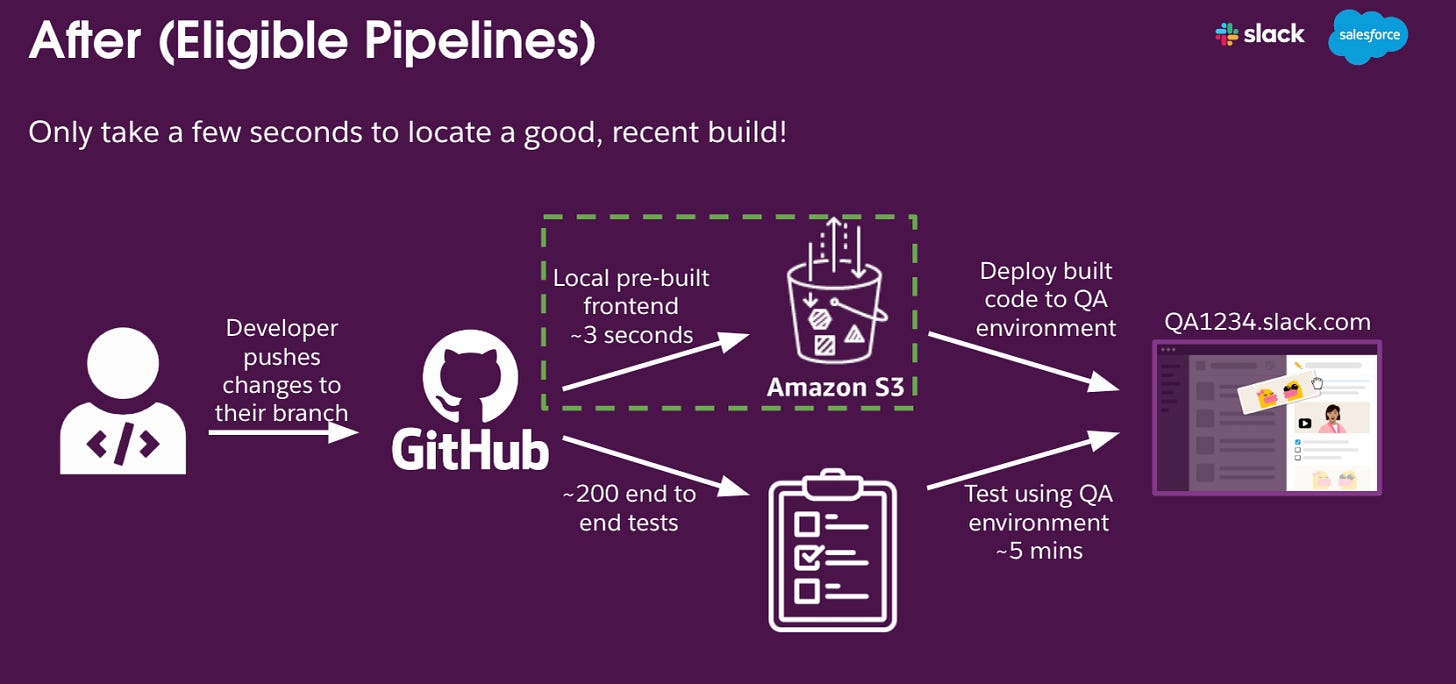
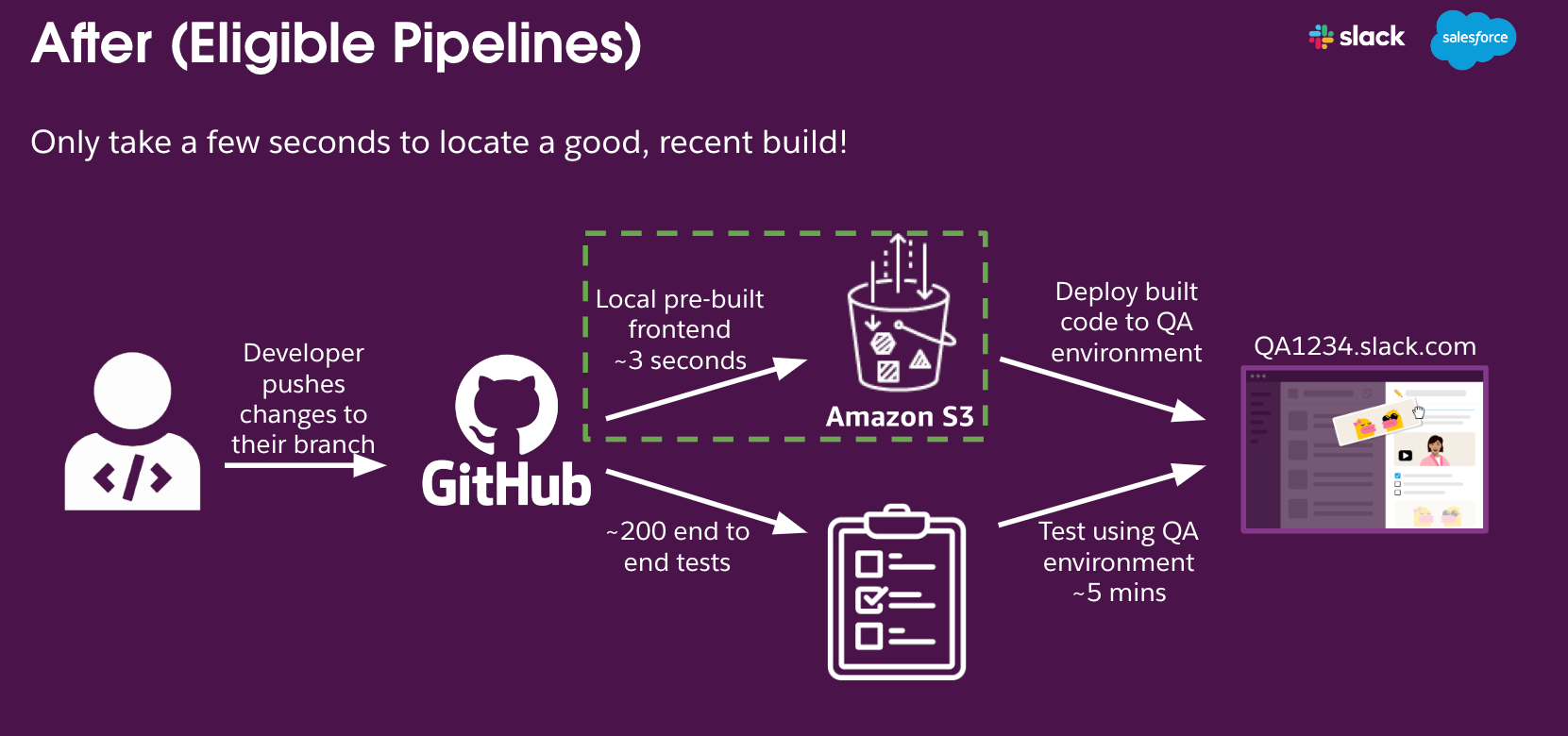
⚡ Average decision time: under 3 seconds
📉 Build frequency: down 60%
3️⃣ 🧱 What Made This Hard?
Scaling this across a monorepo with 100,000+ files came with challenges:
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.