


How Yelp Achieved 1,400x Faster Model Training
How Yelp Achieved a 1,400x Speedup in Neural Network Training Optimizing Ad Click-Through Rate Predictions with TensorFlow and Horovod.

🚀 TL;DR
Yelp supercharged their machine learning training and achieved a 1,400x speedup using a combination of TensorFlow, Horovod, and their custom ArrowStreamServer. They transitioned from Petastorm to a more efficient data streaming solution, optimized GPU scaling, and improved batch processing. Here’s how they did it.
🛠️ What Are The Requirements?
Yelp Needed to Solve Yelp’s ad click-through rate (pCTR) models operate on massive tabular datasets stored in Parquet format on S3. Initially, training 450 million samples took 75 hours per epoch on a single GPU instance. With data growing to 2 billion samples, they aimed to reduce training time to under 1 hour per epoch, facing key challenges:
Inefficient Data Streaming: Petastorm’s rebatching caused performance issues.
Scaling GPU Utilization: TensorFlow’s MirroredStrategy didn’t scale efficiently beyond 4 GPUs.
Managing Compute Resources: Threading issues led to performance bottlenecks and memory overuse.
🌐 Yelp’s Solution: Data and Distributed Training Optimization
1️⃣ Efficient Data Streaming with ArrowStreamServer
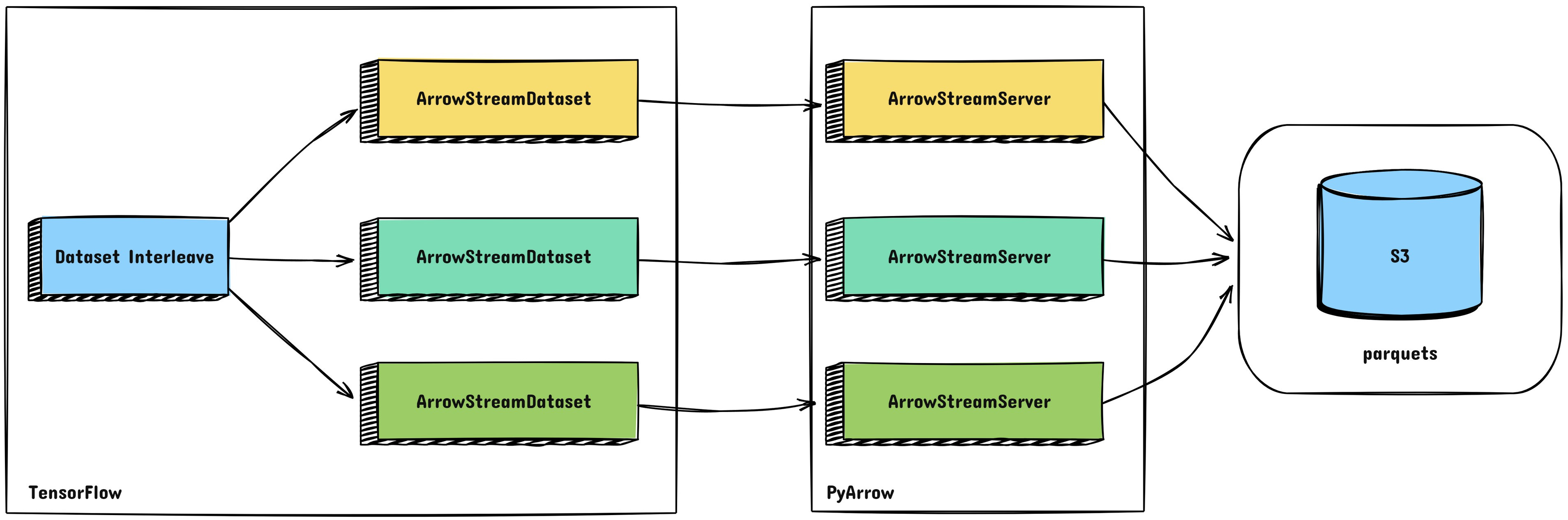
Petastorm was initially used but struggled with tabular data’s rebatching complexity. Yelp developed ArrowStreamServer, a custom PyArrow-based solution that:
Streams data from S3 in optimized batches.
Eliminates the inefficiencies of Python generators.
Leverages RecordBatch streaming for faster consumption by TensorFlow.
Provides flexibility to scale with large datasets while maintaining low latency.
Performance Gains:

By switching to ArrowStreamServer, Yelp achieved an 85.8x speedup in data streaming.
2️⃣ Scaling with Horovod for Distributed Training
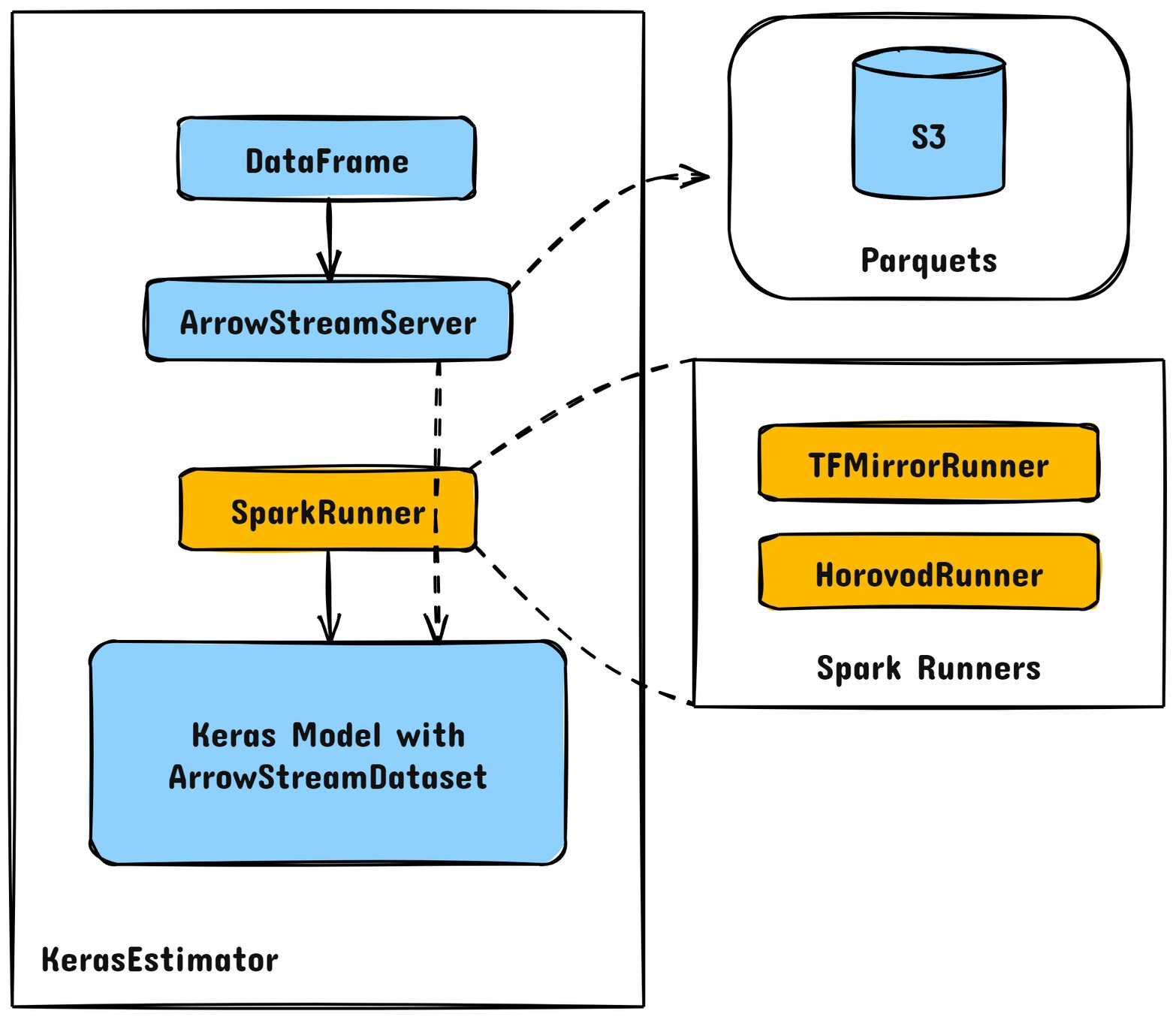
TensorFlow’s MirroredStrategy provided diminishing returns beyond 4 GPUs due to dataset sharding inefficiencies. Yelp moved to Horovod, which enabled:
Linear scaling up to 8 GPUs.
More efficient resource utilization with one process per device.
Memory-efficient gradient conversion from sparse to dense.
Seamless fault tolerance with elastic training capabilities.
This transition led to a 16.9x improvement in model training speed.
Key Challenges and How Yelp Overcame Them
Threading Storms: Thousands of threads caused oversubscription. They resolved this by tuning TensorFlow threading options per GPU:
private_threadpool_size = CPU cores per GPUram_budget = Available host memory per GPUOMP_NUM_THREADS = CPU cores per GPU
Keras Compatibility: Yelp had to override the
train_stepof the WideDeepModel to ensure compatibility with Horovod's distributed optimizer.Data Pipeline Bottlenecks: Transitioning from a batch-oriented to a streaming-oriented data pipeline required rethinking the input pipeline, ensuring that data was fed at a rate that fully utilized GPU capacity without introducing latency.
Checkpointing and Recovery: With distributed training, checkpointing became more complex. Yelp implemented a robust checkpointing mechanism to ensure model state consistency across multiple workers in the event of failures.
🌟 Results: Faster Training and Lower Costs With optimized data streaming and distributed training, Yelp reduced the training time from 75 hours to under 1 hour, achieving a total 1,400x speedup.
Takeaways for Senior Engineers:
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.