
Inside Spotify’s ML Annotation System: Scaling Human + Machine Labeling to Millions
How Spotify combined expert reviewers, custom tooling, and LLM-powered workflows to label content at scale.

Your blueprint to deliver distributed data at scale

Learn to build and deploy applications with a modern, PostgreSQL compatible and distributed SQL database designed to meet you where you are at, whether you are on-prem, hybrid, or multi-cloud. This book is packed with practical guidance to enable developers, architects, and devops teams to build resilient applications that scale effortlessly for their users, all while remaining highly available and essentially indestructible.
🚨 TL;DR
Spotify had a scaling problem. Not with their music streams, but with their data labels.
If you want machine learning models that actually work in production, you need clean, accurate, high-quality labeled data. Not a few thousand rows. Millions.
Doing that by hand? Impossible.
Relying solely on AI? Risky.
So Spotify built something better, a human-machine system designed from the ground up to create labels at scale. It combined expert reviewers, smart tooling, flexible infrastructure, and just enough AI to speed things up without compromising on quality.
This is what it takes to build reliable ML systems in the real world.
📖 What Are We Covering Today?
Why high-quality annotations are the fuel behind ML at scale
How Spotify organized their human experts like a production line
The custom tooling they built to power weird, messy data
What made their infrastructure flexible enough to handle any annotation project
Lessons you can steal for your own ML pipelines (Paid)
Why annotation debt is just as dangerous as technical debt (Paid)
How to future-proof your human-in-the-loop systems (Paid)
🎧 Why ML Breaks Without Labeled Data
Spotify uses machine learning everywhere.
When you search for a song, when podcasts get flagged for moderation, when new releases show up on the right artist page, there is a model making that happen.
But none of those models work without ground truth.
The catch? Spotify doesn’t have just one type of data. They have audio, text, video, images, and metadata often all tangled together in a single piece of content.
And the labels needed for each are wildly different. Labeling a song is not like labeling a podcast. Moderating content in 65 languages is not the same as marking explicit lyrics.
This wasn’t just a volume problem. It was a complexity problem.
👩💻 How Spotify Scaled Human Expertise Like Infrastructure
Most teams treat annotation like a one-off task. Hire a few contractors. Label some data. Move on.
Spotify knew that wouldn’t cut it.
So they built a layered annotation workforce, almost like a customer support org.
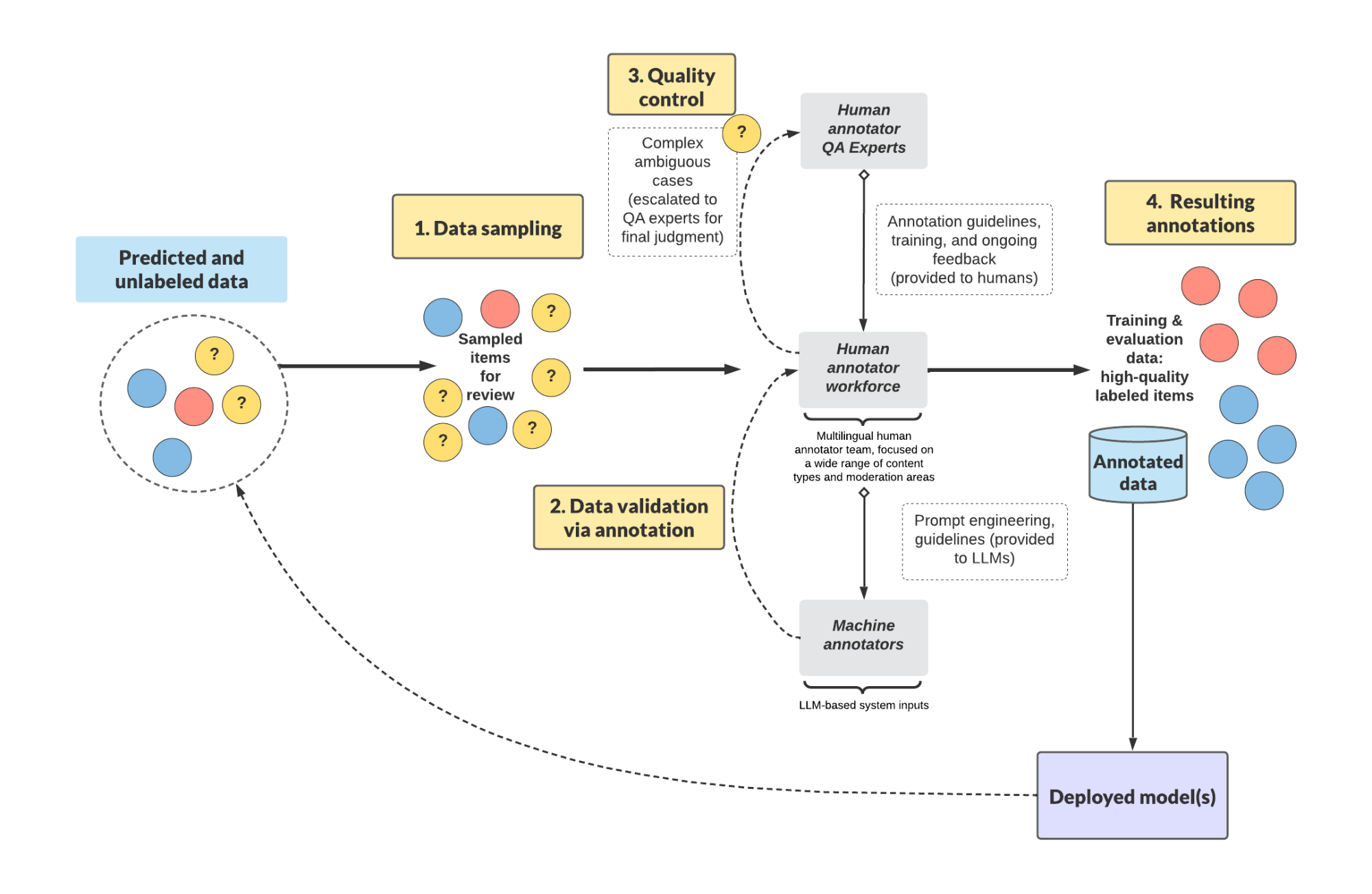
First level: Domain experts who handled the bulk of the annotation work
Second level: Senior quality analysts who resolved tricky or subjective cases
Third level: Project managers who sat between engineering teams and the annotation workforce, making sure everyone stayed aligned
But human expertise alone wasn’t enough.
Spotify also deployed LLM-based systems in parallel. These models could pre-label easy cases, leaving the ambiguous ones for humans. It was never humans vs. AI. It was humans and AI working together.
🛠 The Tools That Made This Work
Spotify didn’t start out with the perfect toolset. Early projects looked like what you would expect: hacked-together scripts, spreadsheets, manual review queues.
That did not scale.
So they built purpose-built tooling for the messy realities of ML data:
Custom interfaces for audio, video, and text annotation
Smart task routing that sent data to the right expert
Real-time dashboards tracking project progress, reviewer agreement, and data quality
Automated escalation for disagreements or low-confidence labels
One of the smartest things they did? They treated annotation like its own product. They didn’t wait for engineers to be in the loop for every new task. The tooling let project managers move fast independently.
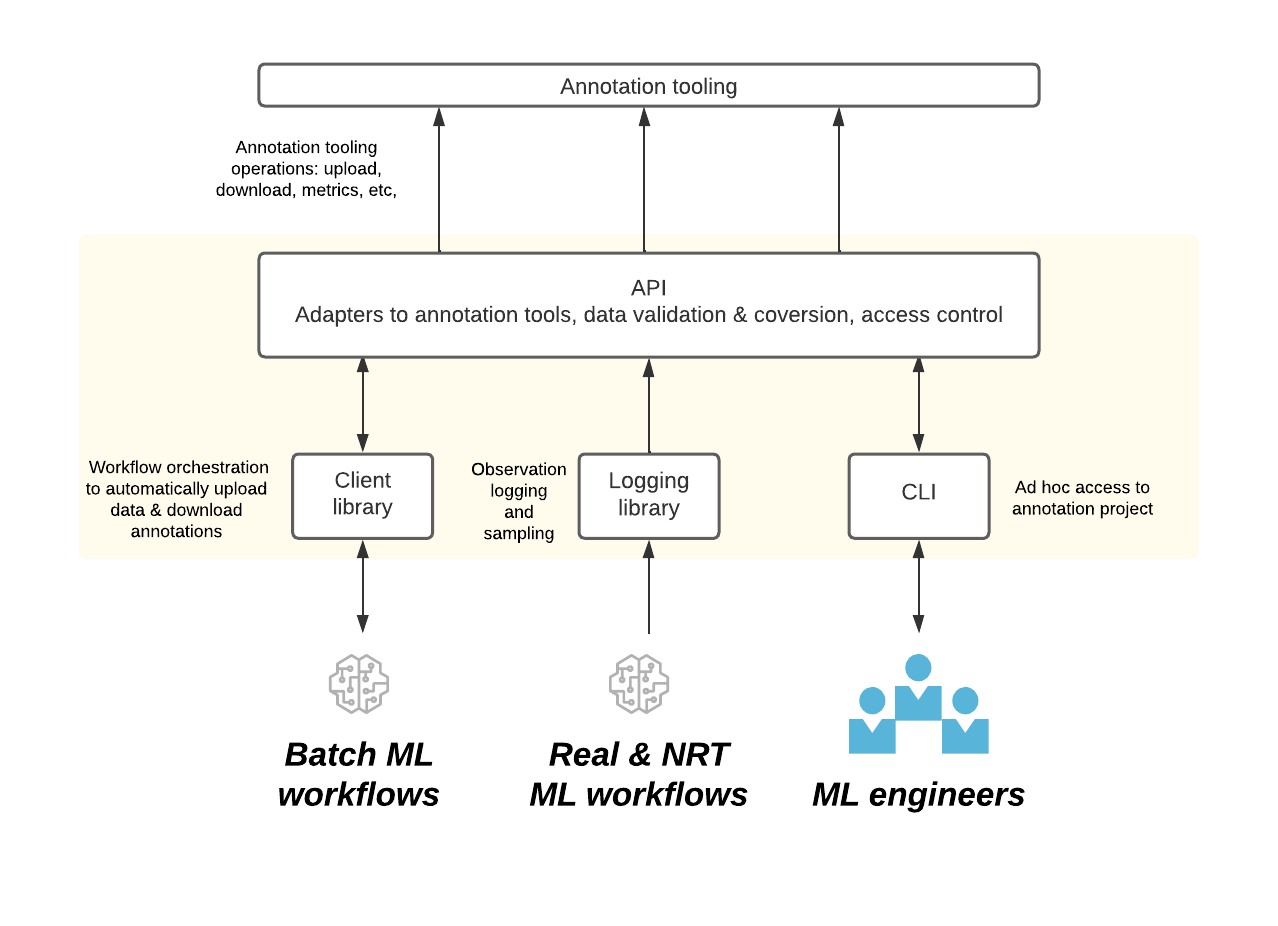
🧱 Infrastructure Built for Messy Reality
Spotify’s ML ecosystem is too large and too weird for a one-size-fits-all tool. They needed infrastructure that played nicely with all kinds of projects — from tiny ad hoc labeling tasks to massive production pipelines.
So they built:
Generic APIs that any tool or workflow could plug into
CLI tools for lightweight projects
Deep integrations with their batch processing and orchestration systems
Annotation data models that worked across audio, text, and everything in between
Basically, any ML team at Spotify could ask for labeled data, and get it, without starting from scratch.
🧠 Lessons From Spotify You Can Steal
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.