
Notion's Data Doubled Every 6 months. So They Built a Datalake
It's always better to build it yourself.

Target Audience: Senior Engineer

📚 tldr;
In 2021, Notion data doubled every 6 months and got to the point where they had hundreds of terabytes of data to process.
Having a dedicated Extract, Load, Transform (ELT) pipeline with Snowflake would take HOURS to ingest.
It was a better idea for Notion to build their own datalake.
This Article is Powered By Multiplayer

Multiplayer auto-documents your system, from the high-level logical architecture down to the individual components, APIs, dependencies, and environments.
Perfect for teams looking to streamline system design and documentation management without the manual overhead.
Work on System Design with teams here:
❄️ What’s Wrong With Using Snowflake?
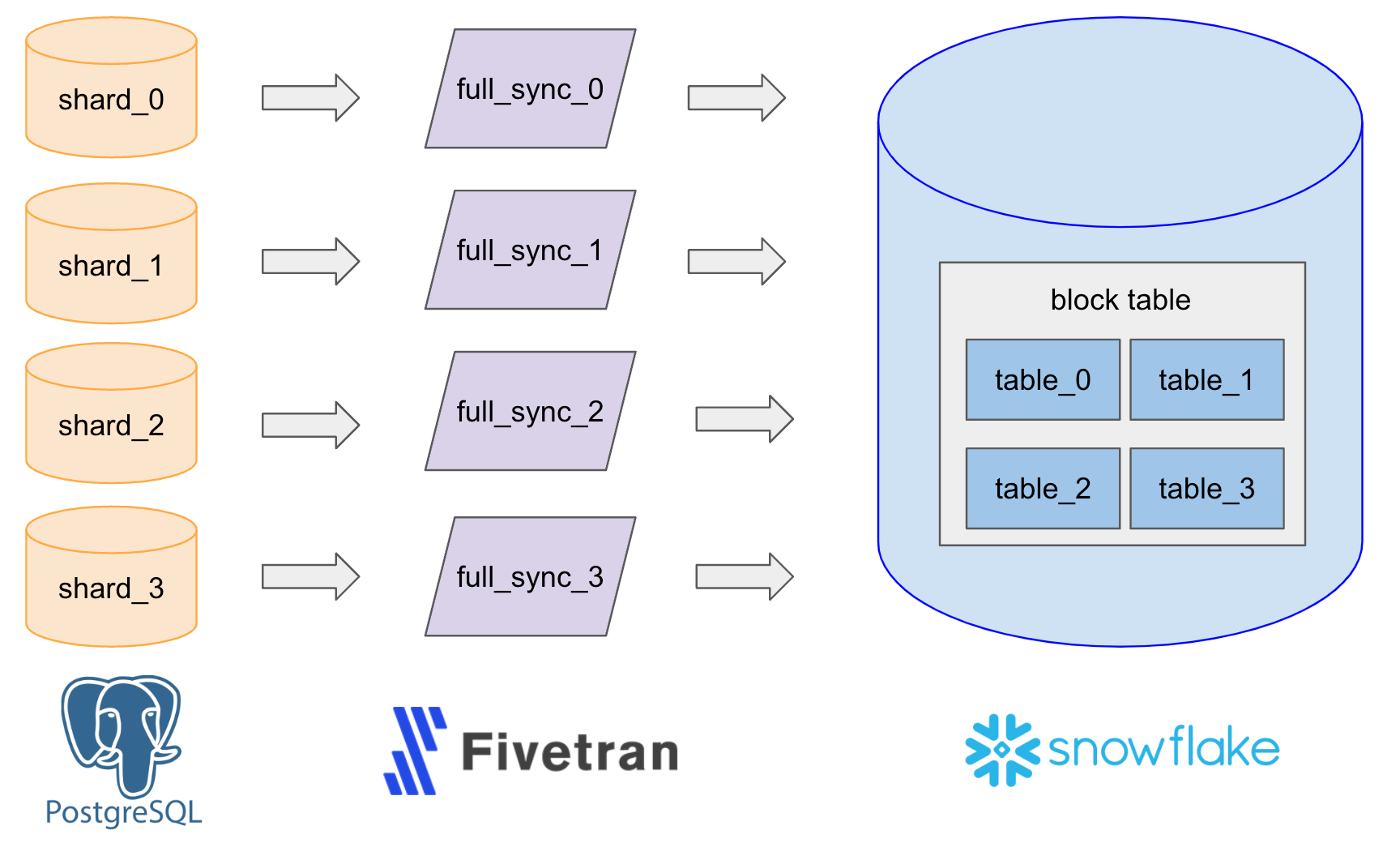
Notion’s architecture in 2021 was an ELT pipeline that worked with PostgreS, FiveTran and Snowflake.
PostGres was set up with a write-ahead log with 480 shards. This means using 480 Fivetran connectors to write to Snowflake tables.
The snowflake tables would be merged together for downstream processing like analytics, reporting, and machine learning.
The biggest problems with this architecture is simplified below (to save you time):
Operability
Monitoring, managing, and re-syncing 480 Fivetran connectors is not maintainable and stressful for on-call.
Snowflake is Slow. (The best argument)
Snowflake is optimized for insert workloads like creating a new document. But with a service like Notion (and Substack), user research shows 90% of operations are update-heavy.
This just means people are updating bullet points and titles instead of creating new pages.
Too much transformation.
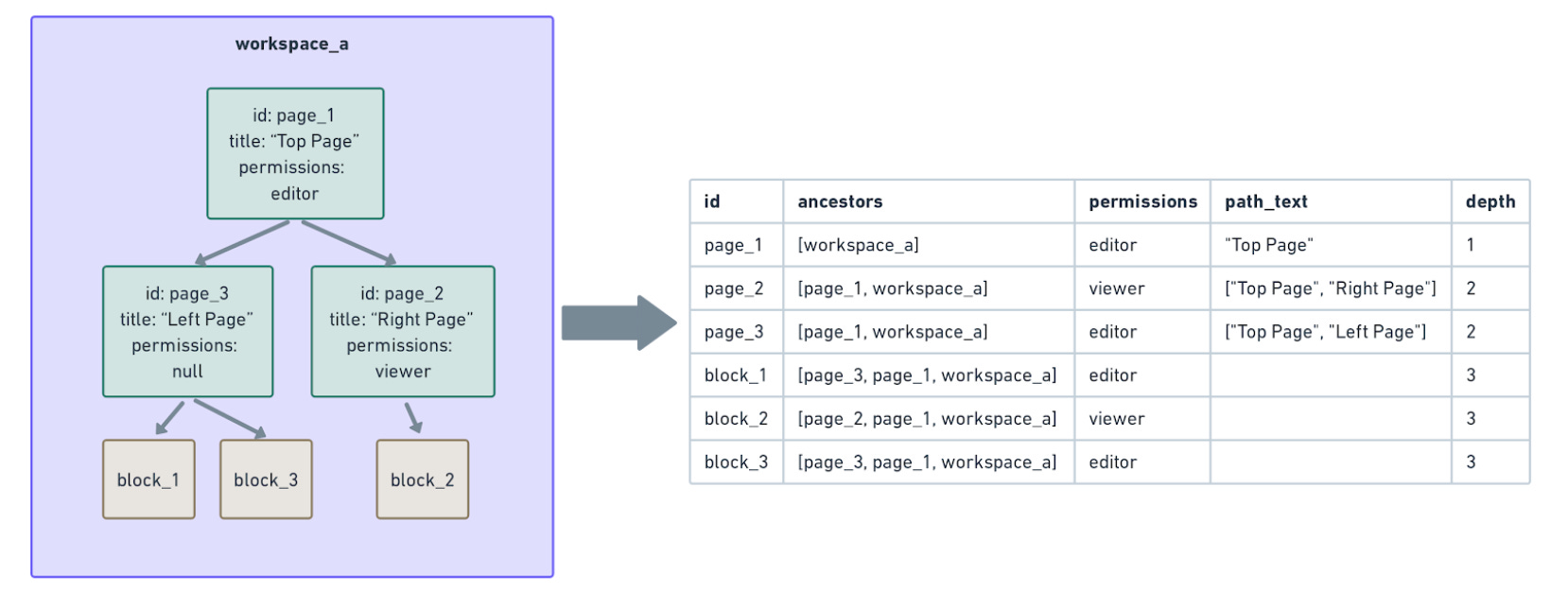
This article won’t focus on permissions, but Notion had a problem where some of their text changes required the right permissions.
The problem is that permissions aren’t on the PostGres table itself and requires expensive computation to check by traversing parent nodes.
This means Notion needs to reliably handle data in strange ways. (Also called denormalization)
⚙️ Something Like This Always Has Requirements. What Were They?
TODO’s
Have a place to handle raw and processed data. At scale of course.
Be faster than Snowflake and handle updates well.
Support denormalization really well.
DON’TS
Don’t drop Snowflake or FiveTran. We’re building an enhancement, not a replacement.
Don’t focus on online support. We’re building a datalake in-house for offline use cases only.
🌨️ The Sky-High level design
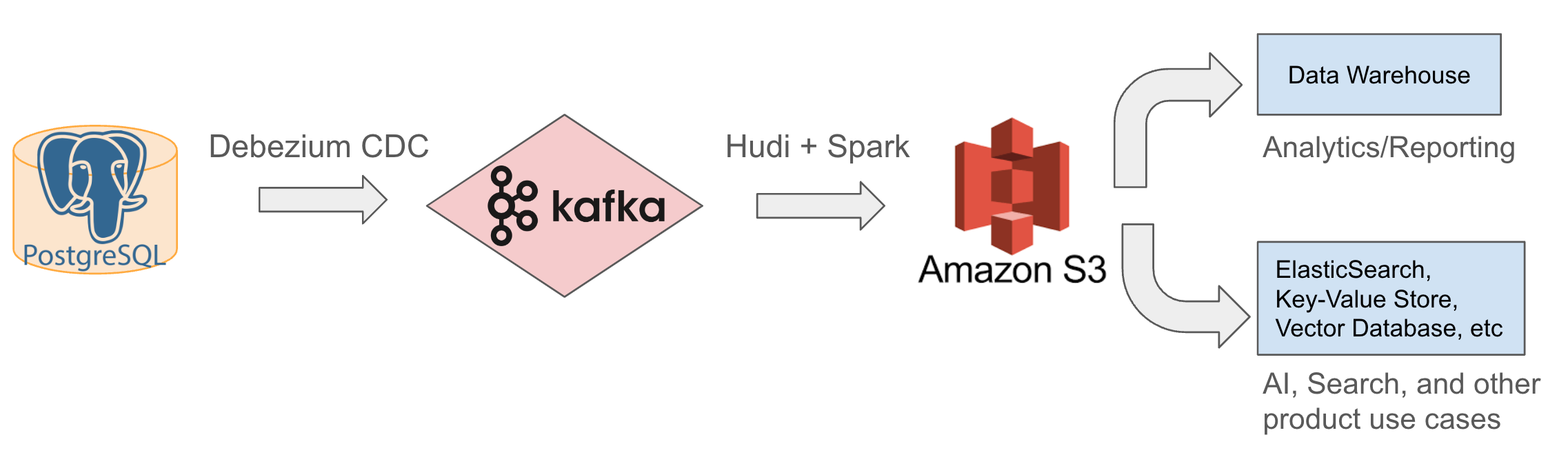
This entire diagram is going to be explained by everything below.
What Are We Using For Our Data Repository?
All our raw and processed data is going to be in S3.
Notion is already built on AWS
S3 Can handle tons of data and supports a lot of other processing engines.
What Are We Using For Data Processing?
We use Spark because it’s easy to onboard and easy to set up.
Spark has User Defined Functions (UDF) to support complex data processing like tree traversals and data denormalization
It supports PySpark for light use cases and Scala Spark for big jobs.
Distributed data processing is supported with easy-to-use configurations.
It’s open-source and widely supported.
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.