
Processing Trillions: How Lyft's Feature Store Grew by 12%, 33% Faster, With Zero Custom DSLs

TL;DR
Lyft’s Feature Store serves 60+ production use cases and grew caller count by 25% last year. They cut P95 latency by a third while handling over a trillion additional R/W operations. The secret wasn’t fancy tech—it was treating ML infrastructure like a product with actual users who have better things to do than learn your system.
🎯 The Problem Nobody Talks About
Here’s what kills most ML platforms: the feature engineering tax.
Data scientists write a killer model. It works great in notebooks. Then they need to:
Rewrite feature logic for production (different language, different compute)
Debug why training features don’t match serving features
Wait 3 sprints for platform team to provision infrastructure
Maintain two separate codebases that drift apart
Six months later, the model’s still not deployed and everyone’s moved on to the next fire.
Lyft decided this was unacceptable. When you’re running a marketplace where every ML improvement directly impacts revenue, you can’t have your ML engineers stuck in infrastructure hell.
🏗️ Architecture That Doesn’t Get In The Way
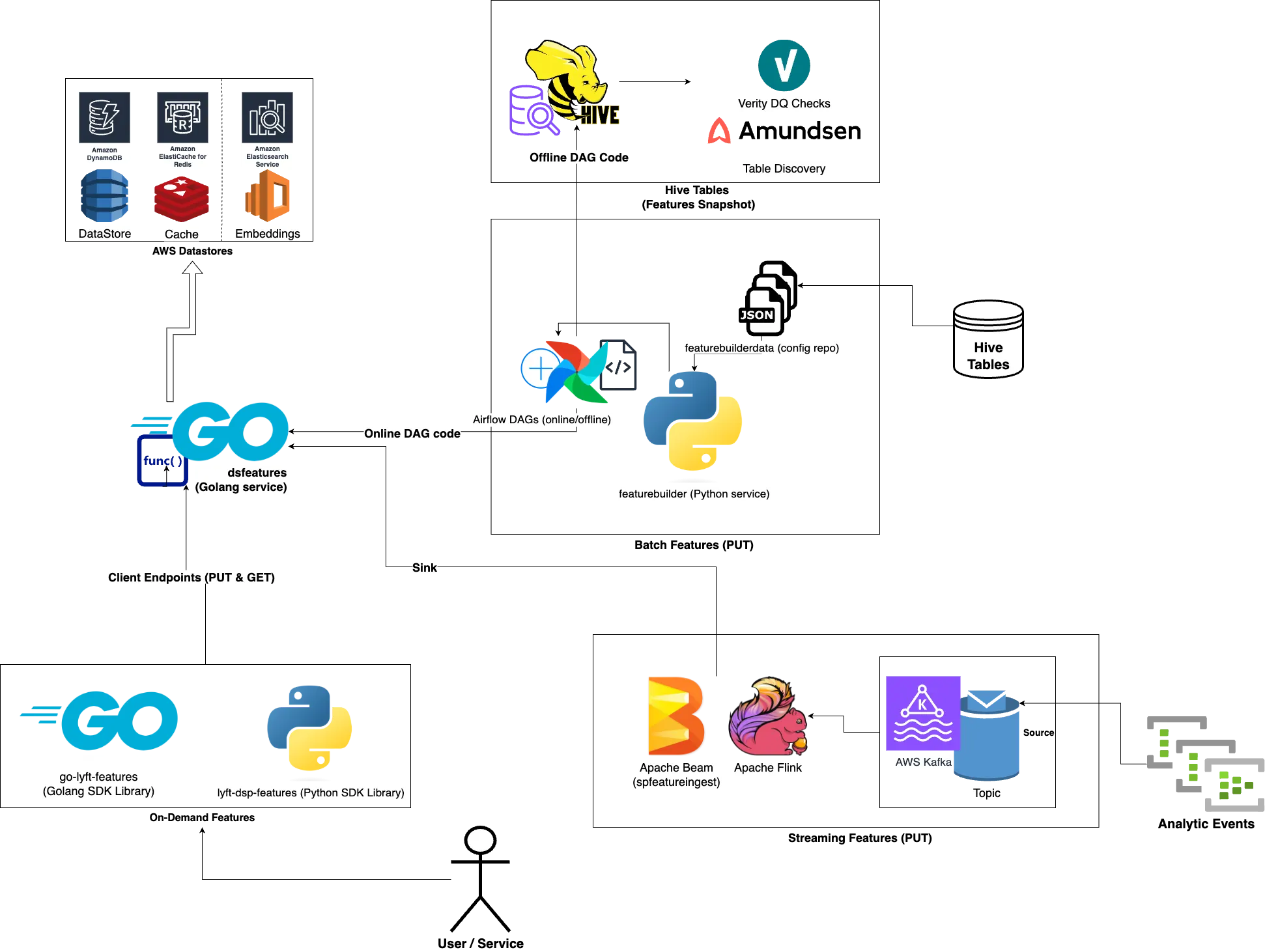
The Three Feature Families
Lyft split their world into batch, streaming, and online. Not revolutionary, but the execution matters.
Batch features (the workhorse):
Customer writes SparkSQL query + simple JSON config
Python cron generates production Airflow DAG automatically
DAG handles compute, storage, quality checks, discovery—everything
Data lands in both Hive (offline training) and DynamoDB (online serving)
Streaming features (the real-time stuff):
Flink apps read from Kafka/Kinesis
Transform data, add metadata
Sink to
spfeaturesingestserviceService handles serialization and writes to online store
Online serving (dsfeatures):
DynamoDB as source of truth
ValKey (Redis fork) write-through cache on top
OpenSearch for embeddings
Go and Python SDKs expose full CRUD
The smart part? Whether you write features via batch DAG, streaming app, or direct API call, they all land in the same online store with identical metadata. No “training/serving skew” headaches.
The Part That Actually Matters
Most feature stores fail because they’re too clever. Lyft succeeded because they made everything stupidly simple:
For feature creation:
SparkSQL query + JSON config. That’s it.
json
{
"owner": "pricing-team",
"urgency": "high",
"refresh_cadence": "daily",
"features": {...}
}sql
SELECT
user_id,
avg(ride_cost) as avg_ride_cost_30d
FROM rides
WHERE dt >= date_sub(current_date, 30)
GROUP BY user_idNo YAML hell. No custom DSLs. Just SQL and basic metadata.
For feature retrieval:
SDK method calls. Get() or BatchGet(). Returns data in whatever format your service speaks.
They optimized for the 90% use case: SQL-proficient engineers who want to ship fast and move on.
