
Scaling Forecasting at Salesforce: From Five Services to Millions of Forecasts
Seamlessly Powering Predictions

What does it take to forecast demand for a multi-cloud infrastructure managing immense resources and high-stakes operations?
For Salesforce, the answer lies in building a custom AI-driven Time Series Forecasting Platform that scales with precision and speed. When the existing system for five core services couldn’t meet the needs of 100+ services, Salesforce’s Infrastructure Data Science (InfraDS) team didn’t just iterate, they reimagined forecasting.
Here’s how they expanded their platform to manage millions of daily forecasts, cut deployment time from weeks to days, and delivered high availability and accuracy across a sprawling infrastructure.
🚀 TL;DR
Forecasting demand for Salesforce's infrastructure goes beyond predicting numbers, it's about preventing costly downtime and optimizing resource management.
Old approach: Five services, weeks to deploy models.
New platform: 70+ use cases, scaling to millions of forecasts daily.
How? They built a scalable platform with these principles:
Configuration-driven flexibility
Seamless scaling with Kubernetes and Spark
“Cattle, not pets” approach to models
What Will We Dive Into Today? 📖
Introduction
What Makes forecasting at scale challenging?
Why this matters?
What are the Requirements?
Inside Salesforce’s new Forecasting Platform
Internal Architecture
How it works in practice?
Lessons for Engineers
Insights & Official Article (Paid)
What is the TimesFM Foundational Model?
Why didn’t Salesforce use it?
🛑 What Makes Forecasting at Scale Challenging?
Forecasting at scale is not just about running more computations; it involves addressing inherent complexities that multiply with each new dataset or use case. Here’s why scaling time series forecasting is a uniquely difficult problem:
1️⃣ Diverse and Evolving Use Cases
Every time series has unique characteristics—trends, seasonality, and volatility. Unlike fields like NLP or computer vision, there isn’t a one-size-fits-all approach for time series forecasting.
Long-range forecasts rely on stability and often incorporate macroeconomic factors like market trends or environmental shifts.
Short-range forecasts, on the other hand, prioritize agility to handle real-time data drift and exclude many external variables.
Balancing these competing requirements across hundreds of services necessitates models that are both robust and flexible.
2️⃣ No Perfect Universal Models
Frameworks like Moirai and TimesFM (More on this in the Paid Section) show promise for scalable and general-purpose forecasting, but simpler models like ARIMA, Prophet, and XGBoost remain essential. These simpler models are valued for their interpretability and low computational overhead, yet managing thousands of such models across diverse datasets presents a significant logistical challenge.
Each model must be fine-tuned for dataset-specific nuances.
Updates to one model can inadvertently disrupt others, especially when models are deployed across shared infrastructure.
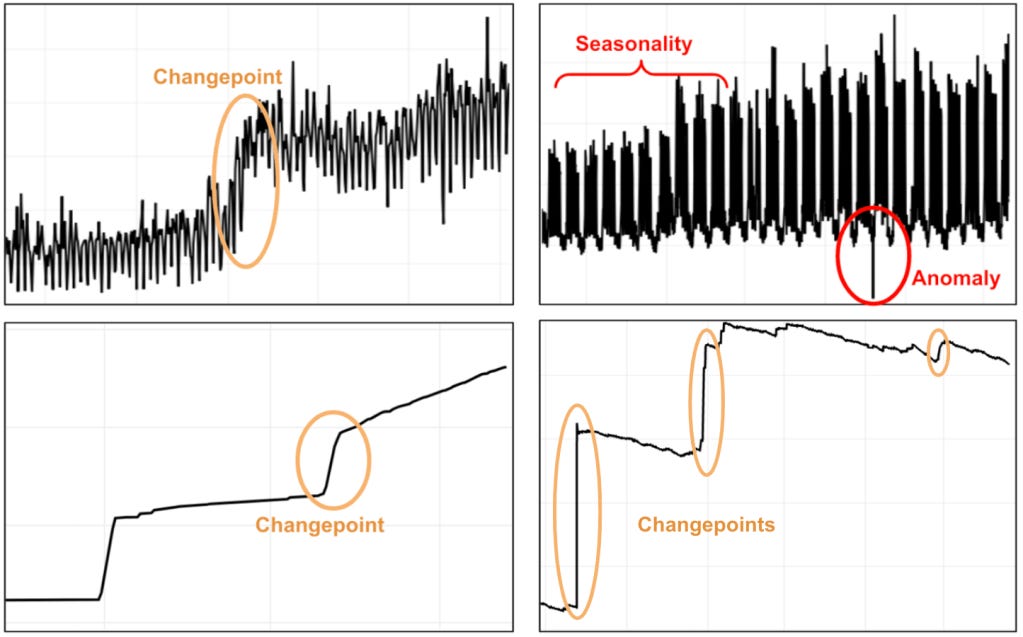
3️⃣ Fragmented Tooling
The lack of a mature Machine Learning Operations (MLOps) ecosystem exacerbates the problem:
Data scientists often start in Jupyter notebooks, manually experimenting with models.
Moving from experimentation to production involves re-engineering code into scalable pipelines, which is time-consuming and error-prone.
Monitoring tools for production models are scattered, requiring bespoke integrations for anomaly detection and accuracy tracking.
Teams often spend more time stitching tools together than improving forecast quality.
4️⃣ Infrastructure Complexity
Scaling from five services to 100+ services means exponential growth in compute demands:
Traditional setups often rely on centralized resources, where heavy compute usage for one service can throttle others.
Transitioning new models to production previously took weeks or months, as each required custom infrastructure code in languages like Python or R.
This complexity frequently led to reinventing the wheel for every new use case, adding unnecessary overhead.
5️⃣ Cost vs. Accuracy Trade-offs
While powerful models like Transformer-based architectures dominate in NLP, time series forecasting depends on lightweight models for cost efficiency. However:
Simpler models must handle hierarchical reconciliations across entities, like forecasting CPU usage for individual servers while maintaining coherence across data centers.
Data drift adds an unpredictable layer of complexity, requiring frequent retraining.
Teams must constantly weigh forecast accuracy against the cost of maintaining models at scale.
6️⃣ Lack of Standardization
With each service having its own nuances, codebases diverge quickly:
Different teams use varied tools (e.g., Python for ML and R for statistical modeling), making collaboration harder.
Integration patterns and deployment strategies differ, adding maintenance costs and slowing innovation.
Forecasting at scale, therefore, is as much an organizational challenge as it is a technical one.
Why Forecasting Matters
Forecasting is not just a technical necessity; it drives business outcomes:
Over-provisioning cloud resources wastes millions in operational expenses.
Under-provisioning leads to customer-impacting downtime.
Solving these challenges require systems that make forecasting scalable, reproducible, and cost-efficient. Salesforce’s approach to tackling these issues highlights how they turned a fragmented process into a streamlined platform, empowering data scientists to focus on what they do best: delivering accurate forecasts.
🤔 Gotcha! So what are the requirements?
The InfraDS team set out with clear goals:
Scale Seamlessly
Deploy models for 100+ services without blowing budgets or risking downtime.
Standardize Without Losing Flexibility
Provide data scientists with tools to iterate quickly while hiding infrastructure complexities.
Ensure High Availability
Robust monitoring, type safety, and seamless rollouts were non-negotiable.
🏗️ Inside Salesforce’s New AI Platform
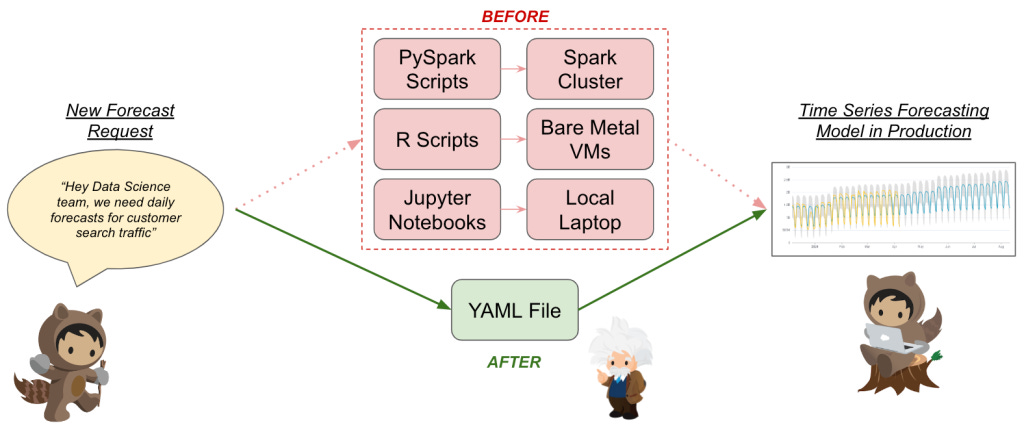
The platform centers on configuration-as-code and a YAML-driven interface, allowing data scientists to focus on models while infrastructure remains invisible. Here's how it works:
1️⃣ Data Ingestion
Raw metrics are ingested using SQL queries with Jinja templating.
2️⃣ Algorithm Flexibility
Supports everything from ARIMA to ML-driven models like XGBoost. Data scientists adjust hyperparameters without touching infrastructure code.
3️⃣ Distributed Orchestration
Models run on Kubernetes or Spark, scaling seamlessly from local experiments to production.
4️⃣ Monitoring and Validation
Built-in tools track model accuracy and enforce type safety using Python libraries like Pydantic.
This structured approach treats models as “cattle, not pets,” enabling faster iteration and lower maintenance costs.
🔍 How It Works in Practice
Imagine you’re forecasting CPU usage for a critical service:
You set up a YAML config for data sources, algorithms, and post-processing thresholds.
The platform automatically deploys your model with type-safe validations.
Metrics like accuracy and seasonality are tracked continuously to ensure reliability.
What used to take weeks now takes days.
💡 Lessons for Engineers
Inspired by frameworks like Metaflow, the approach focused on standardizing and abstracting common data and compute infrastructure requirements for each forecasting project while preserving flexibility in algorithmic development. Key takeaways:
1️⃣ Standardize where it counts, but leave room for creativity.
2️⃣ Prioritize developer autonomy with guardrails to prevent errors.
3️⃣ Treat scalability as a first-class design principle.
Official Article & Exclusive Insights
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.