


Slack Breaks Stuff on Purpose with Chaos Testing
A Guide to Chaos Engineering

Production failures teach expensive lessons. Smart engineering teams learn these lessons cheaper by breaking systems deliberately in controlled environments. This practice, known as chaos engineering, transforms system reliability from reactive firefighting into proactive strengthening. We wrote an edition in the past on how Doordash does this as well, today we will go through chaos testing best practices and how the engineering team at Slack implements them.
Slack’s Wake-Up Call
January 29th, 2024 brought a stark lesson for Slack's engineering team when their internal Kibana dashboards went dark. The culprit? A full disk on their Elasticsearch cluster, coupled with a two-year-old backup that proved useless. Engineers lost access to critical application performance data, and worse, lost their carefully crafted dashboards and visualizations.
The architectural decision to co-locate Kibana and Elasticsearch on the same hosts came back to haunt them. While Elasticsearch can be configured as a standalone cluster for Kibana, their setup meant storage and application were tightly coupled. When disk space ran out, both went down hard.
Embracing Controlled Chaos
The incident catalyzed a complete transformation of Slack's reliability approach:
Modernizing their Elasticsearch architecture by decoupling storage from application nodes
Implementing robust backup systems with monitoring and alerts
Rewriting outdated runbooks based on hard-learned lessons
Setting proper S3 retention policies
Regular testing of recovery procedures
The Chaos Experiment
Rather than hope their improvements worked, Slack's team took an unconventional approach: they scheduled a "break it on purpose" session. On a quiet Thursday morning, engineers gathered to deliberately crash a development Kibana cluster.
The controlled destruction revealed:
Alert systems successfully triggered when disk space filled
Previously unknown firewall rules needed documentation in infrastructure-as-code
Their one-hour recovery target wasn't achievable with manual steps
Runbook commands needed clarity and better formatting for high-pressure situations
The experience led directly to automation. What started as a manual recovery process transformed into a single CLI command that could restore a complete Kibana backup from cloud storage. Later, when migrating their development Kibana instance to Kubernetes, this improved process reduced downtime to just 30 minutes.
Most importantly, this wasn't treated as a one-off exercise. The team made breaking things a regular practice, turning the traditionally dry work of system maintenance into an engaging team activity that continuously improves their reliability.
Other Real-World Chaos Scenarios
Dependencies Going Dark
Simulate complete failure of critical dependencies like Redis, Kafka, or your primary database. This reveals hidden assumptions in your code and tests failover mechanisms.
Example Outcome: A recent test showed our service continuing to operate on stale cache data long after its Redis cluster failed, a subtle but dangerous failure mode we've since corrected.
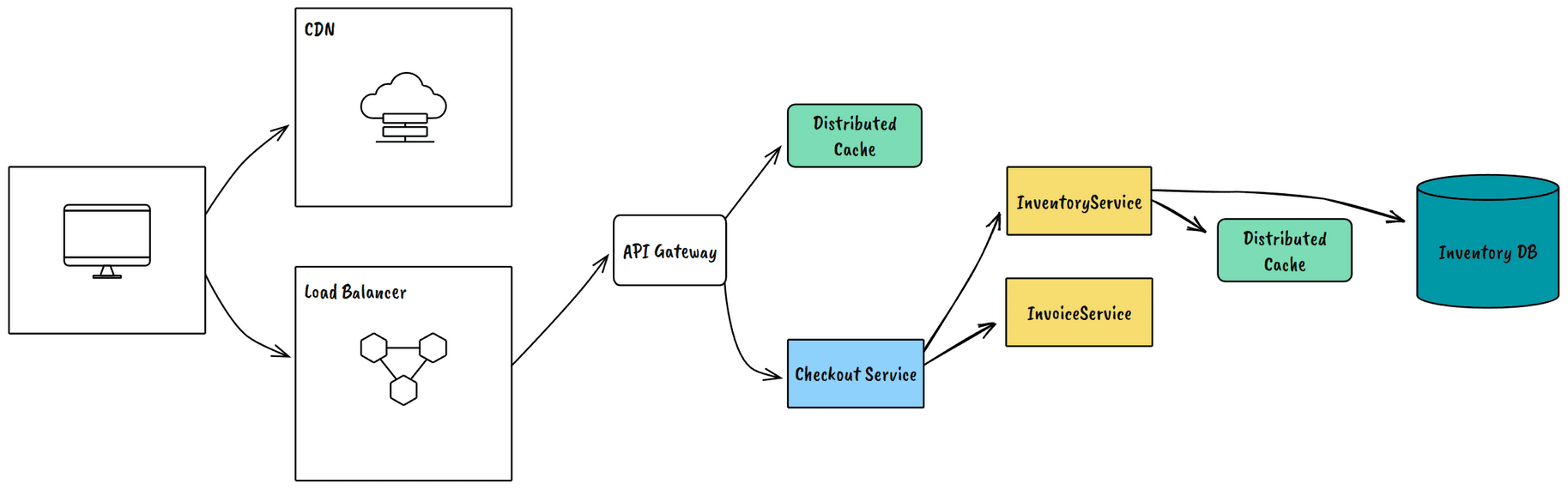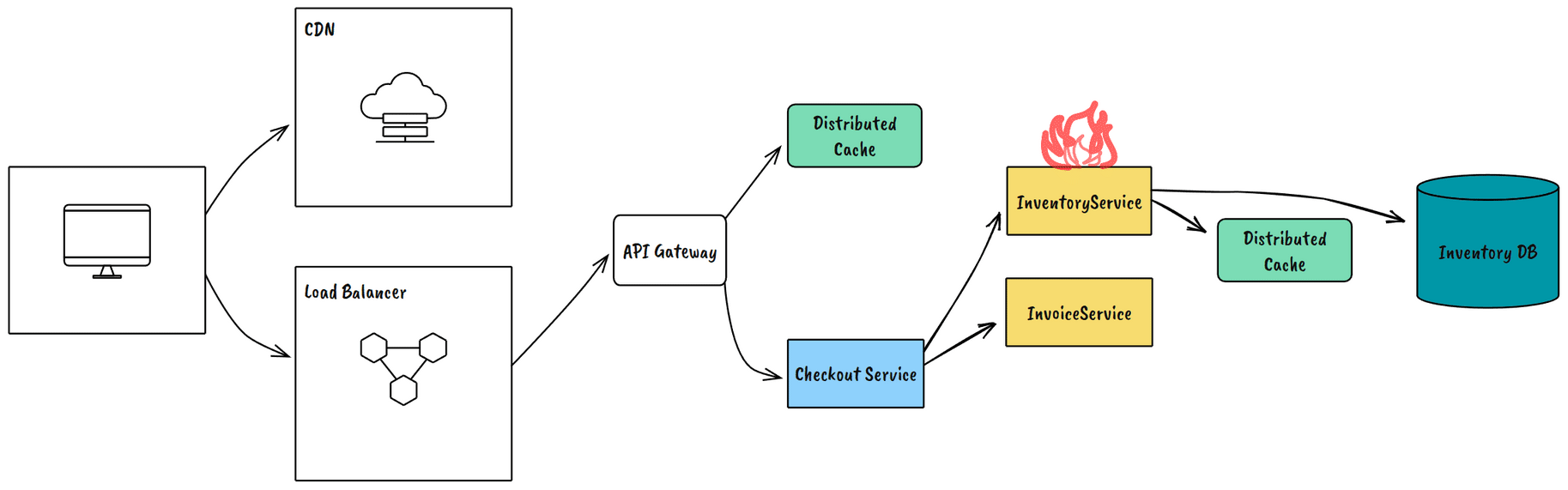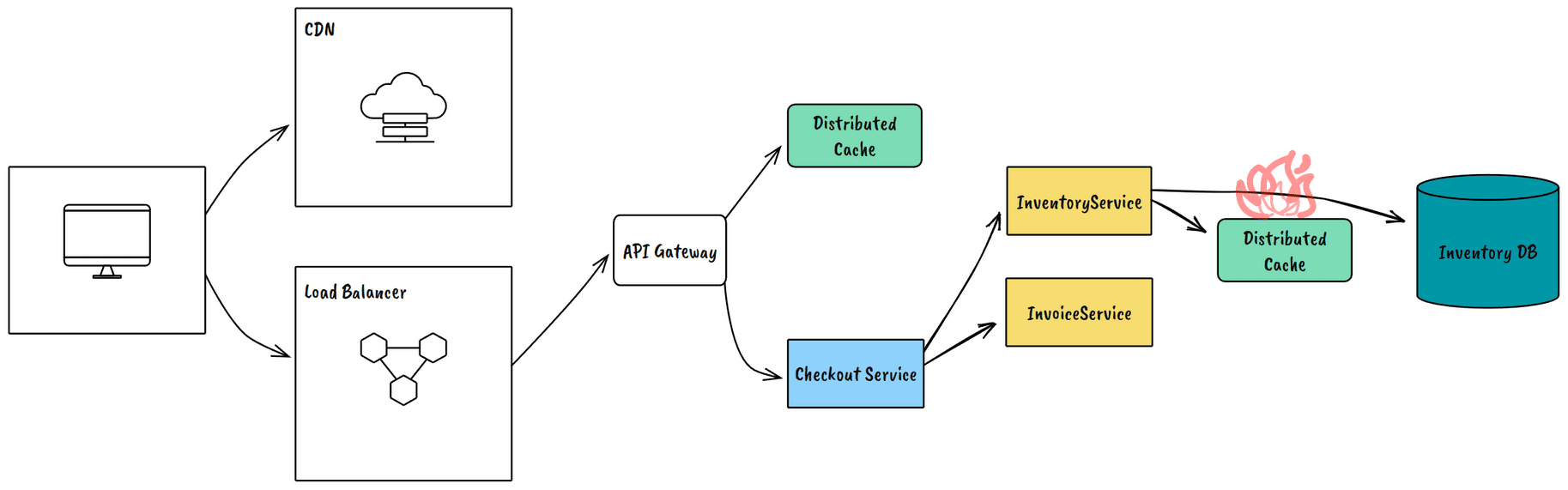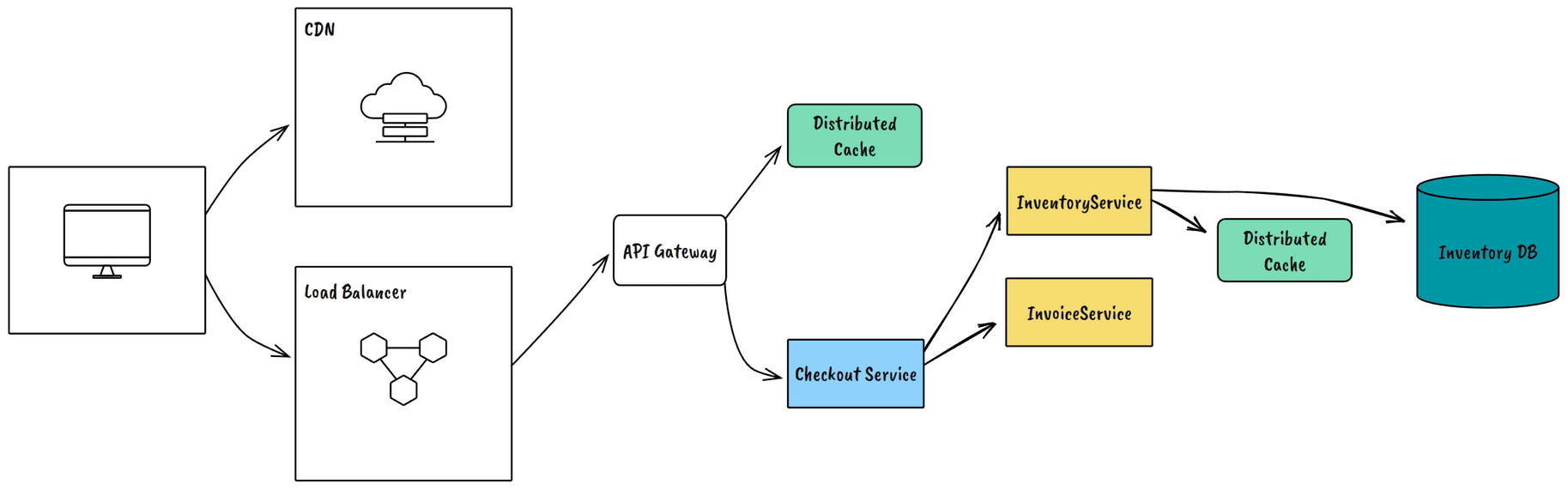
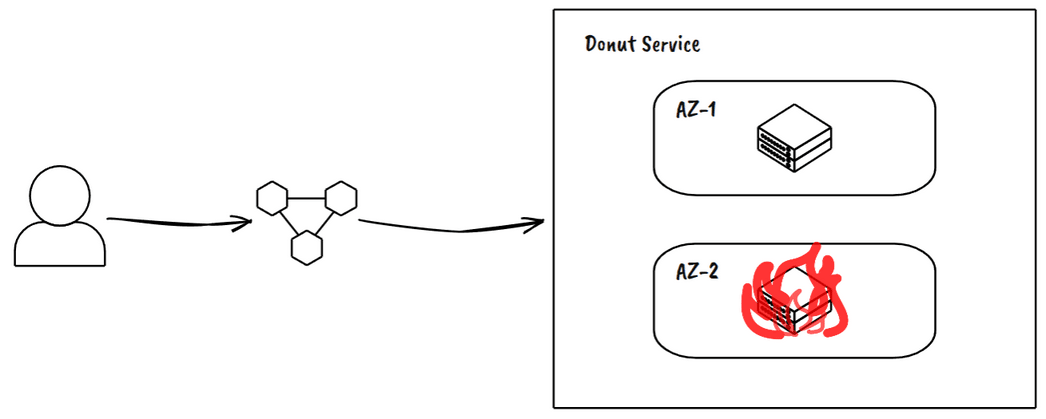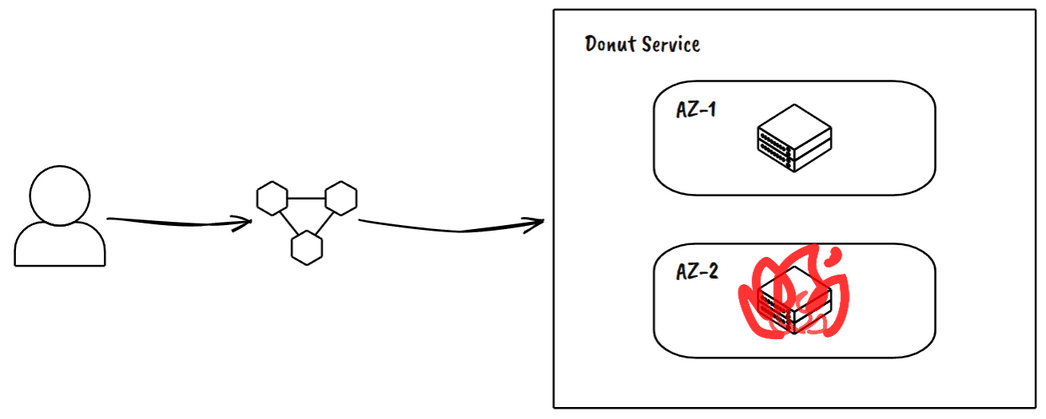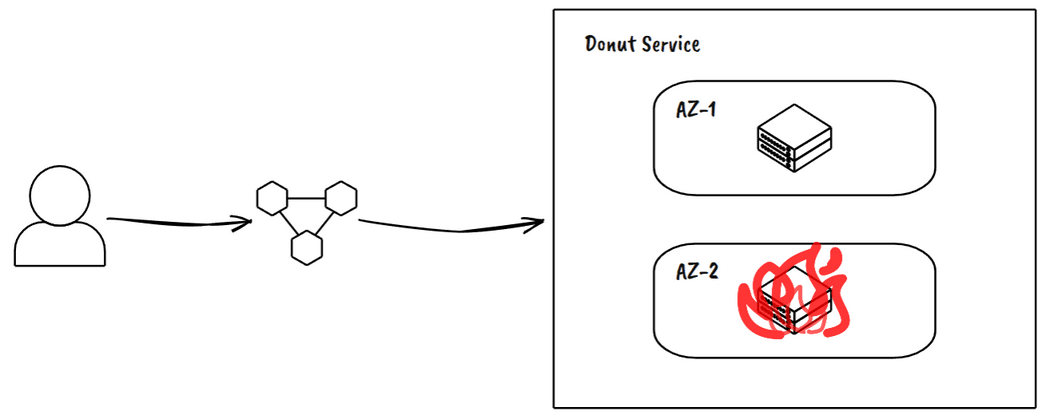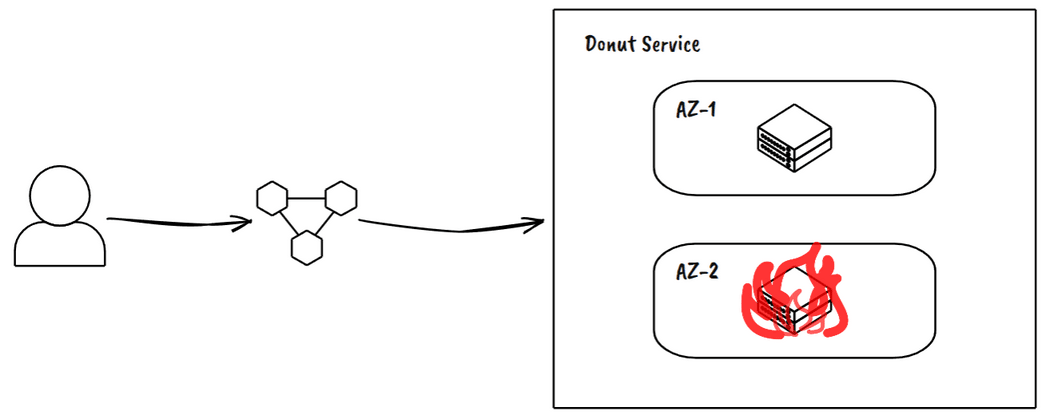
Zone Failures
Take down an entire availability zone. This validates your multi-AZ architecture and exposes configuration problems in load balancers and service discovery.
Example Outcome: Our first zone failure test revealed several services hard-coded to specific AZ endpoints.
Network Partition
Split your network to simulate connectivity loss between services. This tests timeout configurations and retry logic.
Example Outcome: We discovered numerous cases where default timeouts were too long, leading to resource exhaustion during outages.
Resource Exhaustion
Fill disk volumes, consume available memory, or saturate CPU. This validates monitoring, alerts, and auto-scaling responses.
Example Outcome: A disk-full test revealed our logging system would crash instead of gracefully degrading.
Load Testing Under Degraded Conditions
Run peak traffic patterns while critical systems are impaired. This validates graceful degradation and helps quantify minimum viable system health.
Example Outcome: We found several features could be gracefully disabled to maintain core functionality.
Building a Culture of Resilience
"Complex systems usually operate in failure mode."
This principle guides modern system design. Instead of hoping systems won't fail, engineers should assume they will and prepare accordingly. Regular chaos experiments help teams:
Discover hidden system vulnerabilities
Build confidence in recovery procedures
Identify automation opportunities
Transform maintenance from a burden into an engaging challenge
Post-Mortem Process for Failed Chaos Tests
Failed chaos tests can be seen as gifts, they're production incidents without the production pain. When a chaos test fails unexpectedly, you've discovered a system weakness before it could impact real users. These failures should be treated with the same rigor as production incidents, but they provide a unique opportunity to learn and improve in a controlled environment.
I've previously written about effective post-mortem writing in the edition: "Writing Post-Mortems: A Tech Lead's Guide to Learning from Failure" You can read it here.
Key benefits of rigorous post-mortems for chaos test failures:
They build a knowledge base of system failure modes
Engineers practice incident analysis in a low-pressure environment
Documentation and runbooks get tested and improved
Teams align on what "good" recovery looks like
Recovery automation opportunities become clear
Building Team Confidence
Regular chaos testing transforms incident response from a source of stress into a practiced skill. Teams who test regularly handle real incidents with noticeably more confidence and coordination.
The goal isn't to prevent all failures, that's impossible. The goal is to make failure boring, routine, and manageable.
Setting Up a Chaos Testing
Prerequisites
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.