
Slack doesn't want to use your data for their models
To build trust, or to avoid problems?

TLDR;
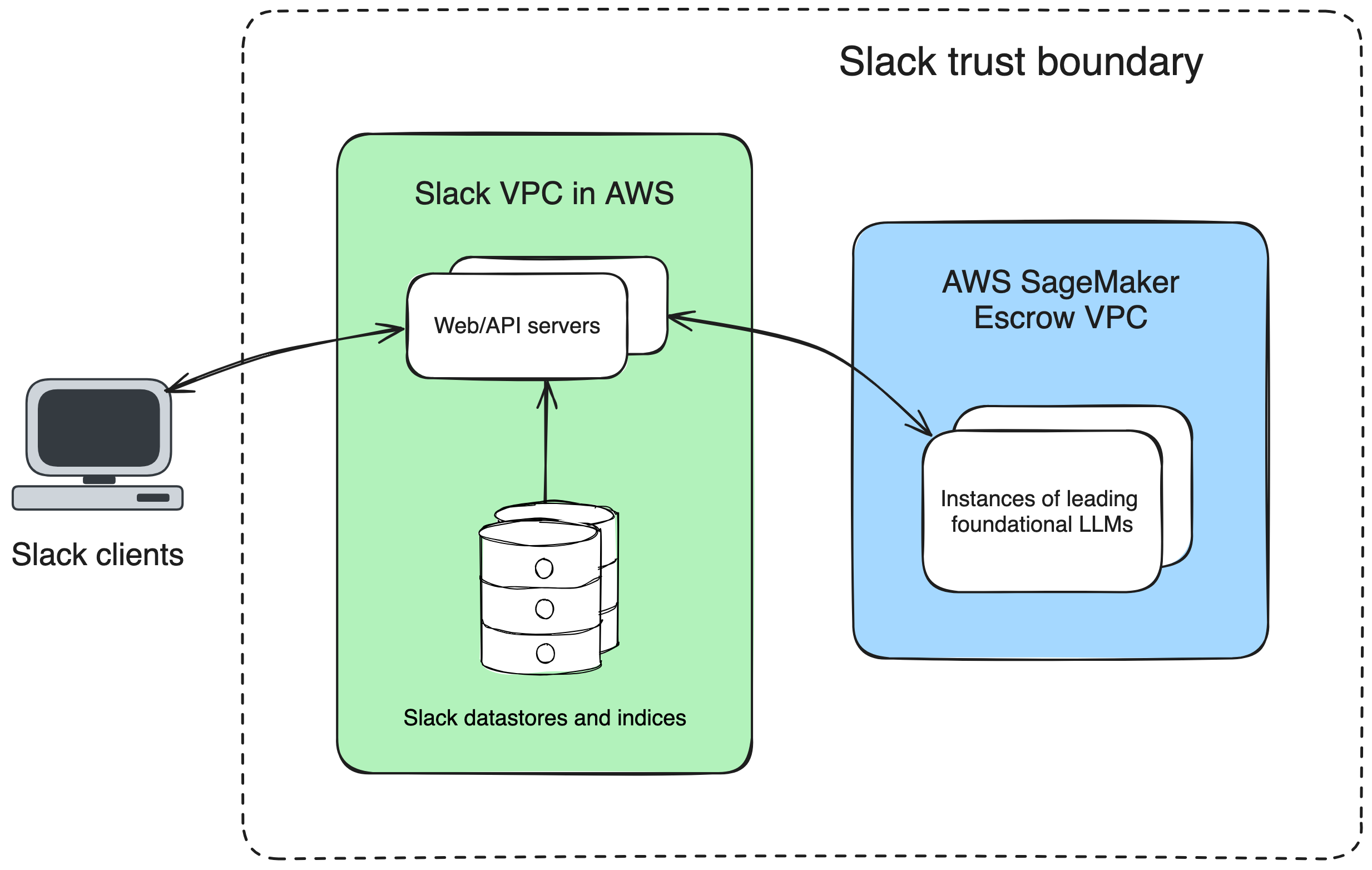
Slack built their Gen AI model off of reading messages in channels only. They used AWS SageMaker to keep all their data in a VPC.
Problem:
Customer data is more important than anything else. But Slack needs to build an AI offering since 90% of AI users reported being more productive.
Requirements:
Straight from the official article:
Customer data never leaves Slack.
We do not train large language models (LLMs) on customer data.
Slack AI only operates on the data that the user can already see.
Slack AI upholds all of Slack’s enterprise-grade security and compliance requirements.
Not training LLM on Customer Data?
Slack uses off-the-shelf models instead of training their own models with customer data.
A big reason for this is to maintain customer trust because if your AI response leaks information from a private chat channel, no one is going to be happy.
Using RAG - Retrieval Augmented Generation (RAG)
For every request, add all the context. Do this to avoid having states and avoid building a model that retains data.
Slack uses RAG by passing in all the context from a company’s work space to the models for every task
The Latency Problem
RAG can only handle so much context at once. There’s a limit to how many messages or data a user can send before a Slack AI can process that to return a meaningful response.
They don’t have a solution for this. Just waiting on the day context windows get bigger and bigger.
Using AWS SageMaker
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.