
Stripe Built Their Own Database With 99.999% Uptime.
Because MongoDb wasn't good enough.


Target Audience: Senior Engineer
📚 tldr;
Stripe built their own database called DocDB because none of the existing solutions were good enough.
MongoDB was close, but Stripe needed something with even more reliability and 0 data migration downtime.
This Article is Powered By Multiplayer

Multiplayer auto-documents your system, from the high-level logical architecture down to the individual components, APIs, dependencies, and environments.
Perfect for teams looking to streamline system design and documentation management without the manual overhead.
Work on System Design with teams here:
🔧 Let’s build it in house. What’re the requirements?
Straight from the official article, here’s their list of requirements for DocDB
Ensuring top uptime, durability, and performance. Strong consistency is not a concern.
Limit database functions to prevent query issues.
Support sharding for horizontal scalability.
Enforcing multitenancy quotas.
Have strong access controls enforced with authorization policies.
This database will be built in GoLang on top of MongoDB with an emphasis on sharding.
📈 Making DocDB Scaleable
Quick Reminder: What is sharding?
It’s when you take a larger dataset and split it up across multiple databases. Splitting up the data is called sharding. Each of those smaller databases is called a “shard”.
Sending the request
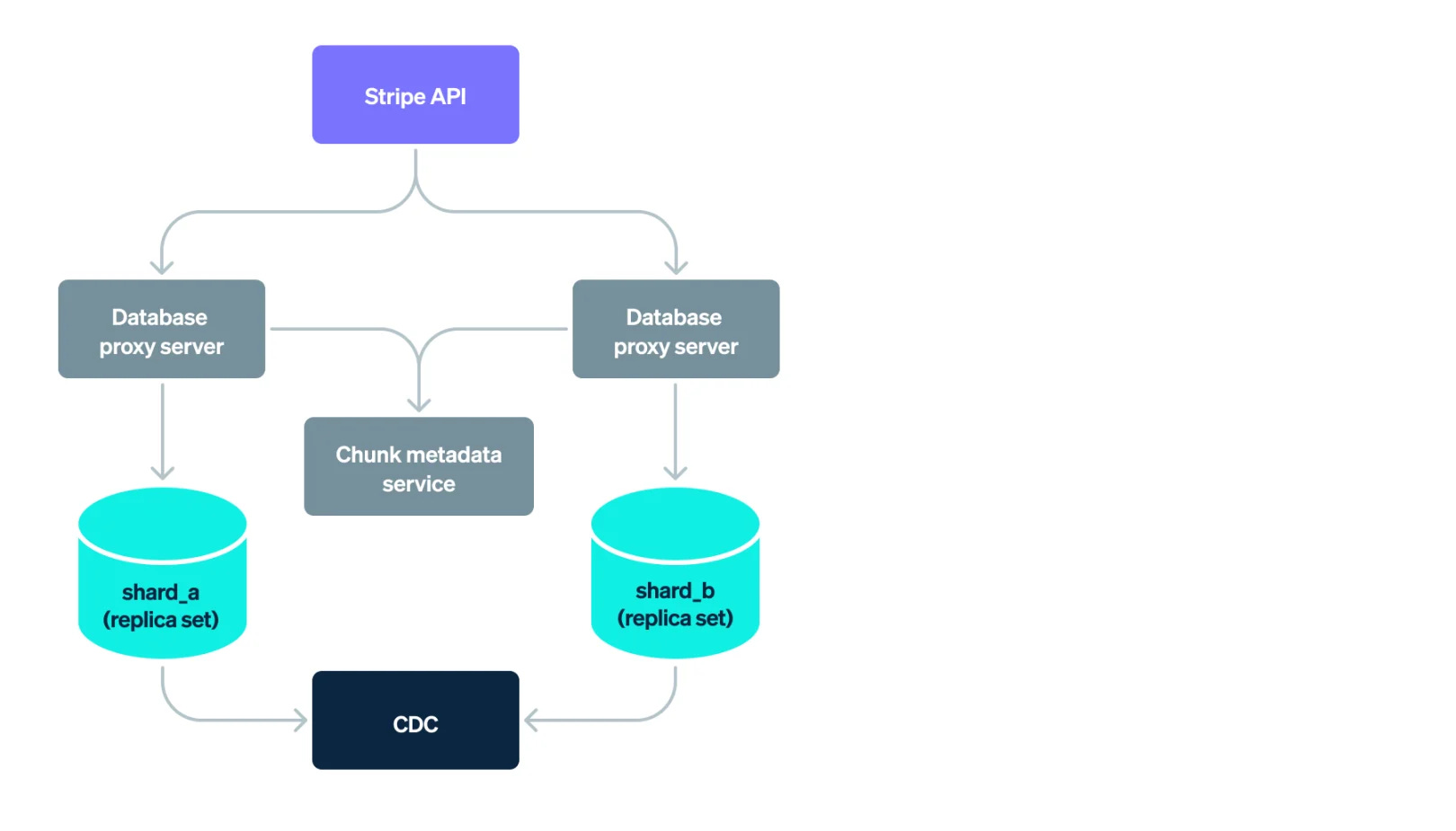
There’s thousands of database shards across all of Stripe’s products. When an application queries a database proxy server, it parses the query, routes it to shards, combines the results, and returns them to the application.
The Routing problem
When there’s an API request to get the data, it gets complicated figuring out which shard to send the query to.
Stripe’s solution is to use a “chunk metadata service”, a routing service to look up the relevant shards for the request.
⚙️ Explaining the Flow All Together

(An example of a sharding algorithm)
A Stripe API request will get sent to a database proxy server.
That server will ask the “chunk metadata service” to learn what shards to fetch.
Data from all the shards will be fetched and combined together.
Write changes will be written to a Change Data Capture pipeline to keep track of all the changes.
But how does this migrate data with 0 downtime?
It doesn’t. DocDB alone wasn’t enough, so Stripe needed to design the Data Movement Platform.
To build this, Stripe kept these additional requirements in mind:
Data is consistent and complete. Something DocDB alone lacked.
Availability. Millions of businesses transact on stripe, so migrations should take only a few seconds.
Granularity and adaptability. Stripe needs to be able to migrate data from any shard to any other shard at any time.
Consistent performance. The original shard shouldn’t have performance issues when migrating.
🧠 Stripe’s Big Brain Design with Data Movement Platform.
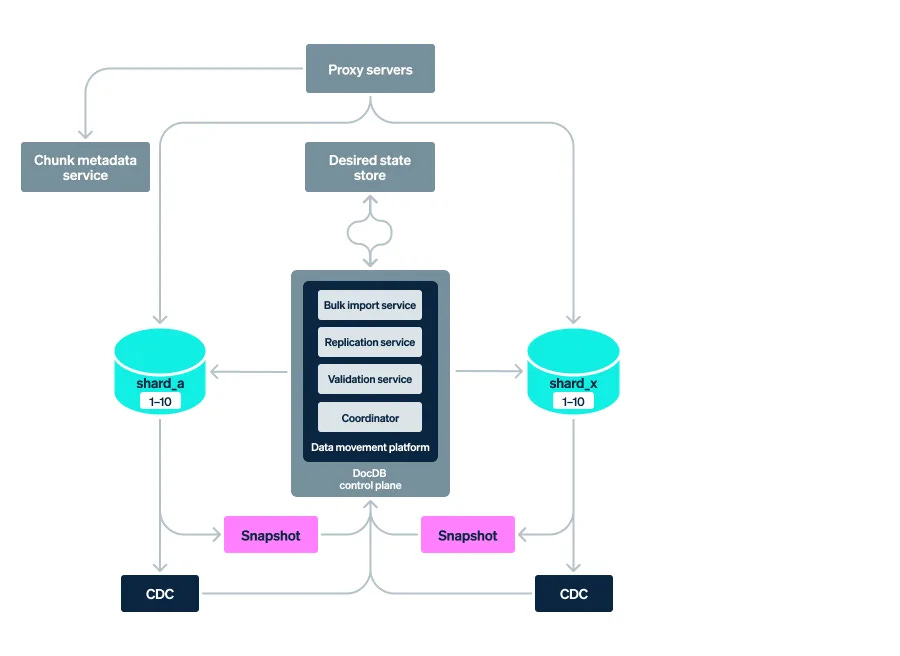
1. Start the migration
To start the migration, the “chunk metadata service” in DocDB registers which source shards intend to send data to target shards.
Indexes will also be built on target shards for faster writing.
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.