
The Economics of NoSQL Design
Trading joins for real-time materialization with MongoDB Atlas Stream Processing.

If you cut your teeth on relational databases, the join is almost sacred. It’s the optimizer’s playground: given a normalized schema, the database figures out the most efficient way to stitch your data back together. With the right indexes, it feels effortless and even beautiful.
But MongoDB challenges that worldview. It doesn’t try to be a relational database in disguise. Instead, it says: don’t join at read time if you can shape your data at write time.
The philosophy is simple:
Store together what you read together.
Duplicate data if it reduces runtime complexity.
Optimize queries by shaping documents to match access patterns.
To a relational engineer, this looks like breaking the rules. To a document-oriented system, it’s how you get predictable, low-latency reads at scale.
The Pain of Joins in MongoDB 😖
1. The “Fragmented Data” Problem
Imagine your Order spread across five collections: customer info, shipping address, payment status, product details, and promotions. To reconstruct an order, you’re forced into $lookup gymnastics. Each additional lookup adds latency, burns CPU, and pushes you toward multi-document transactions for updates.
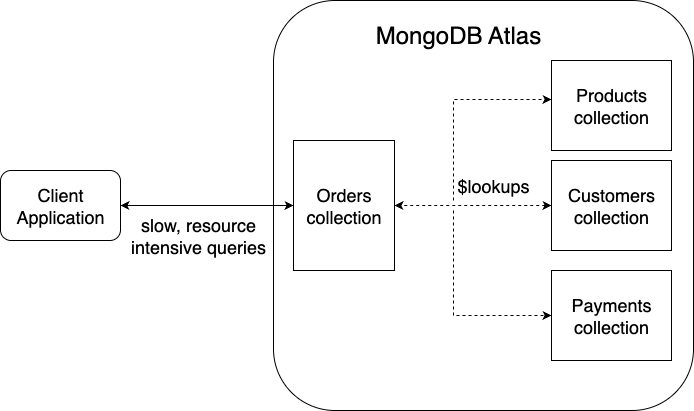
The result?
Reads slow down because you’re doing mini-ETL jobs on every query.
Writes slow down because you’re maintaining consistency across collections.
Code complexity grows because your application logic carries the burden of stitching everything together.
What looked elegant on a whiteboard becomes a drag in production.
2. The “Microservice Dead End”
Now drop this into a microservice world. Each service has its own database for autonomy. Your order service owns orders, your catalog service owns products. What happens when the reporting dashboard needs a joined view?
$lookupwon’t cross databases.Federated queries exist but are slow and designed for analytics, not real-time.
You end up with brittle sync jobs or synchronous API calls that turn one dashboard query into a cascade of inter-service calls.
The dream of autonomy becomes a nightmare of hidden dependencies.
The Shift: CQRS + Event Processing ⚡
The solution isn’t “optimize joins harder.” It’s rethinking the model.
Command Query Responsibility Segregation (CQRS) gives you a clean separation:
Command side (writes): normalized, transactional, focused on correctness.
Query side (reads): denormalized, pre-joined, optimized for speed.
The magic is in the bridge between the two: events.
When you create an order, you don’t wait until a query needs it to piece everything together. You publish an OrderCreated event. A stream processor consumes that event, pulls in related context (product, customer, payment), and materializes it into a query-optimized collection.
That collection is the query side of CQRS—ready to serve your application with a single, fast read.
This model shifts complexity:
Instead of recomputing relationships on every query, you compute them once, at the right time.
Instead of pushing work onto your operational database, you push it onto a stream processor.
It’s a conscious trade: more work at write time, dramatically less work at read time.
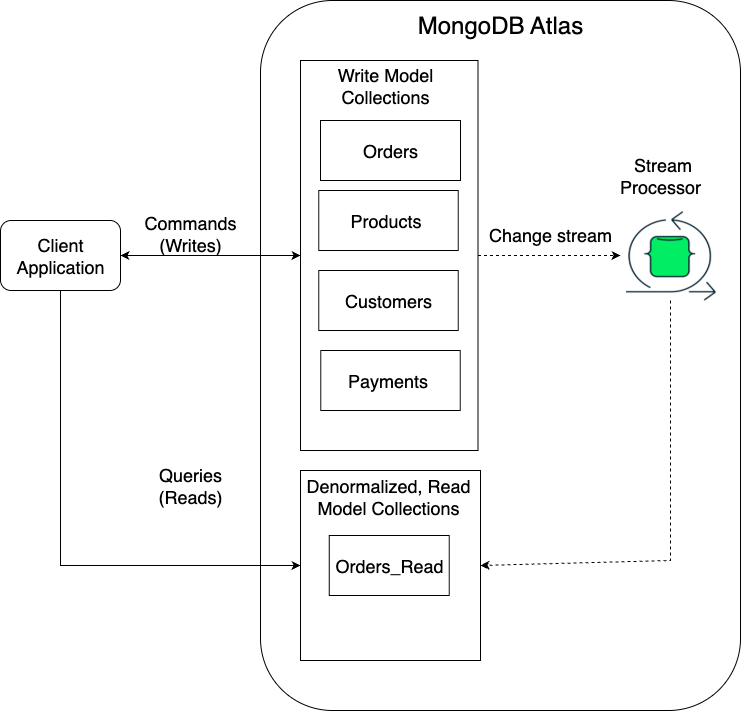
For a microservice architecture, here is what the CQRS pattern would look like:
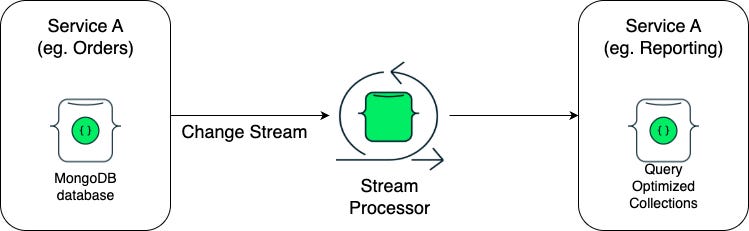
Why It Works 🚀
Speed
Think of joins as assembling IKEA furniture on demand every time you want to sit down. Pre-materialization is having the couch ready in your living room. Reads are just… sitting down.
Efficiency
Your primary DB stops doing double duty as both source of truth and heavy query engine. Stream processors built for throughput take on the joining, aggregating, and enrichment. Your operational workload shrinks.
Cost Savings
In cloud economics, CPU and RAM are expensive, storage is cheap. By trading runtime CPU cycles for denormalized storage, you spend less while serving more. This is why seasoned teams can downsize cluster tiers after adopting CQRS patterns.
Predictability
Joins are variable in cost—sometimes milliseconds, sometimes seconds, depending on data distribution. Materialized reads are boring: O(1) lookups against pre-joined collections. Predictability is underrated until you’ve lived through firefights caused by query latency spikes.
MongoDB Atlas Stream Processing 🛠️
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.