
Understanding Retry Storms: What They Are and How to Deal With Them
Mastering resilience in the face of retry storms.

Retries are a vital part of making distributed systems resilient. They help applications recover from transient faults (temporary issues like network glitches or timeouts) without human intervention. But retries can cause chaos when mismanaged, turning a small problem into a system-wide failure. This phenomenon is known as a retry storm.
Let’s examine what retry storms are, why they occur, and how to avoid them. Along the way, we’ll draw lessons from real world systems to make this more tangible.
What Will We Dive Into Today? 📖
Introduction
What Are Retry Storms?
Why Do Retry Storms Happen?
How to Avoid Retry Storms
Exponential Backoff with Jitter
Retry Budgets
Circuit Breaker Pattern
Token Bucket Rate Limiting
Monitoring and Adaptive Adjustments
Reacting to a Retry Storm: What to Do When One Strikes
Load Shedding
Engage Circuit Breakers
Adjust Retry Mechanisms
Scale Up!
Communicate!
Write a post-mortem
Lessons from Real-World Systems and Official Links (Paid)
Coinbase Incident Post-Mortem: Lessons from a Retry Storm
Azure Storage: A Retry Storm Postmortem
AWS S3: Exponential Backoff with Jitter
Google Cloud Spanner: Adaptive Rate Limiting
What Is a Retry Storm? 🌩️
A retry storm happens when multiple clients or services retry failed operations all at once. The downstream service, already under strain, gets bombarded with an even heavier load. Instead of fixing the problem, retries worsen it, sometimes pushing the system into a complete collapse.
Retry storms are especially dangerous in distributed systems, where multiple components rely on the same downstream service. A single failure can ripple through the entire system.

Why Do Retry Storms Happen? 🌪️
Retry storms usually stem from poor retry policies and inadequate handling of transient faults. Here are the main culprits:
Synchronized Retries: Clients retry at fixed intervals without variation, creating waves of traffic that overwhelm servers.
Unlimited Retries: When retries aren’t capped, the load can grow exponentially, causing resource exhaustion.
No Backoff: Immediate retries amplify the strain on an already struggling service.
Nested Service Dependencies
In systems with nested services, retries from one service can trigger retries in downstream services. For example, if Service A calls Service B, which in turn calls Service C, and all three retry failed requests, the load on Service C can become exponentially worse. The deeper a service sits in the dependency chain, the more it suffers from compounding retries.Retry Anti-patterns: Poorly implemented retry logic doesn’t consider the health of the system or adjust to its state. Microsoft has documented this problem in detail in their retry storm anti-pattern guide.
How to Avoid Retry Storms 🌤️
Analyzing Failure Points to Avoid Retry Storms
Preventing retry storms starts with identifying weak points in your system and testing how it behaves under failure. Regularly simulating stress scenarios helps you uncover bottlenecks and refine your retry and load management strategies.
Disaster Day Example
Simulate a database latency increase (e.g., from 50ms to 500ms) to observe:
Queue Growth: Monitor requests piling up and causing delays.
Retry Behavior: Check if retries amplify the problem or synchronize into bursts.
Metrics: Analyze queue depth, error rates, and request amplification factors.
Disaster testing reveals vulnerabilities like piling requests or runaway retries before they impact production. Use these findings to optimize retry policies, add load shedding, and implement circuit breakers to build a more resilient system.
Use Exponential Backoff with Jitter
Exponential backoff spaces retries over increasing intervals: 1 second, 2 seconds, 4 seconds, and so on. Adding jitter (randomized delays) prevents retries from happening in lockstep. This avoids synchronized traffic spikes, which are often the root of retry storms.
Microsoft’s retry pattern guide explains why combining backoff with jitter is critical for distributed systems.

Limit Retry Attempts with Budgets
A retry budget sets a cap on the total number of retries allowed for a client or operation within a specific timeframe. When the budget is exhausted, retries stop, and the failure is logged.
Retry budgets prevent unbounded retries from overwhelming a system. They also ensure fairness, so a few clients can’t monopolize server resources during an outage.
Add a Circuit Breaker
A circuit breaker stops retries entirely when a service is in an unhealthy state. This gives the system time to recover. Circuit breakers work in three states:
Closed: Requests flow normally.
Open: Requests are blocked to reduce load.
Half-Open: A few requests are allowed to test if the service is healthy again.
Circuit breakers are especially useful when transient issues escalate into prolonged outages. Microsoft details their usage in the circuit breaker pattern guide.
Use Token Bucket Rate Limiting
The token bucket algorithm controls the number of retries a system will accept. Here’s how it works:
A bucket holds a fixed number of tokens.
Each retry consumes one token.
Tokens are replenished at a steady rate.
When the bucket is empty, retries are paused until more tokens become available.
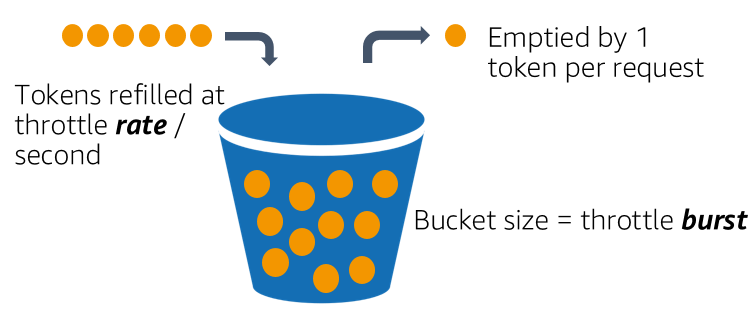
This strategy helps manage bursts of traffic while maintaining a sustainable retry rate.
Monitor and Adjust in Real-Time
Good retry logic doesn’t operate in a vacuum. It needs feedback from the system. Metrics like retry rates, server CPU usage, and request amplification factors can guide adaptive adjustments. For example, you might throttle retries or extend backoff intervals when system load is high.
Reacting to a Retry Storm: What to Do When One Strikes ⚡
When a retry storm is already in progress, quick and effective action is critical to stabilize the system and prevent a full-blown outage. Here’s how to respond:
1. Load Shedding
Once you’ve confirmed this is a retry storm by analyzing TPS graphs across systems, prioritize shedding non-critical traffic. Dropping low-priority requests reduces the load on critical resources, allowing vital services to continue functioning.
Example: For an e-commerce platform, prioritize checkout and payment processing while temporarily rejecting analytics or inventory updates.
How to Implement: Use existing load-shedding mechanisms, like rate limits or priority-based request handling, to fail non-critical requests early.
2. Engage Circuit Breakers
Circuit breakers help protect downstream services already under stress by blocking additional retries. This gives the system time to recover and prevents retries from compounding the issue.
What to Do:
Identify failing services in the retry path.
Manually or programmatically "open" circuit breakers to stop retries to those services.
Outcome: Allows time for the service to stabilize while reducing strain on the rest of the system.
3. Throttle Retry Rates
If retries are overwhelming the system, adjust retry intervals dynamically to reduce their frequency:
Increase backoff intervals to stagger retry attempts further apart.
Apply jitter to prevent synchronized retries.
Cap retries per client using a retry budget.
4. Scale Up Temporarily
If your system supports autoscaling, increase capacity to handle the surge in retries. This is a temporary fix but can buy you time to implement longer-term solutions.
Scale What?: Add more compute resources, database replicas, or API instances.
Considerations: Ensure scaling doesn’t just delay the inevitable or move the bottleneck elsewhere.
5. Communicate with Stakeholders
Let internal teams and external stakeholders know what’s happening. If necessary, trigger customer-facing status updates to manage expectations. Transparency reduces confusion and builds trust.
6. Write a Post-Mortem
Once the storm has passed, write a detailed post-mortem to analyze the incident. A post-mortem is a structured document that outlines:
What Happened: Describe the sequence of events leading to the storm.
Root Cause: Pinpoint the triggers and contributing factors.
Impact: Quantify the effect on the system and users (e.g., downtime, performance degradation).
Actions Taken: Explain what was done to resolve the issue.
Lessons Learned: Identify gaps in the system and areas for improvement.
Follow-Up Actions: Define clear steps to prevent recurrence, like adjusting retry policies, adding circuit breakers, or refining load shedding thresholds.
A post-mortem is not about assigning blame. It’s about learning from the incident to build a more resilient system. Sharing the findings with relevant teams ensures everyone benefits from the lessons learned.
Lessons from Real-World Systems & Links ☀️
Coinbase Incident Post-Mortem: Lessons from a Retry Storm
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.