
🛠️ When Elasticsearch Reached Its Limits, DoorDash Built Their Own Search Solution
How DoorDash tackled the challenges of scale, complexity, and performance with a custom-built search engine.

🚀 TL;DR
Imagine searching for “vegan burger” in your DoorDash app and getting tailored options, complete with prices, customizations, and delivery times. Precision search like this isn’t just a feature, it’s a necessity when serving millions of users.
But delivering precision at scale is hard. DoorDash’s search system, that was powered by Elasticsearch at the time, was hitting limits. It wasn’t designed to handle the complexity of item-store relationships or the sheer volume of updates and queries DoorDash needed to support.
So DoorDash built their own search engine, leveraging Apache Lucene as its foundation. This resulted in:
50% reduction in p99.9 latency
75% decrease in hardware costs
A multi-tenant, scalable platform tailored for growth
This isn’t a recommendation to abandon Elasticsearch, it’s a story of when building custom solutions is justified. Let’s explore why they made this choice and how they delivered a solution built for their future. We will be looking at:
1️⃣ 🚀 Why DoorDash Built Their Own Search Engine
2️⃣ 🛑 Why Elasticsearch Couldn’t Keep Up
3️⃣ 🤔 OK, So What Are the Requirements?
4️⃣ 🔍 What Is Apache Lucene?
5️⃣ 🏗️ Inside DoorDash’s Search Engine
💡 More Insights, Quiz & Official Link (Paid)
Query Understanding Pipeline: Synonyms, Geo-Filtering, and Boosting
Machine Learning for Ranking: User Behavior and Real-Time Signals
Quiz Questions and Answers
What replication mechanism does DoorDash use?
How do search stacks isolate workloads in DoorDash’s architecture?
What are the key steps in DoorDash’s query understanding pipeline?
How does ML improve DoorDash’s ranking logic beyond traditional methods?
What role does the control plane play in managing search stacks?
👉 Link to the Official Article
🛑 Why Elasticsearch Couldn’t Keep Up
Elasticsearch is robust and widely used, but DoorDash faced specific challenges that it wasn’t equipped to solve.
Scaling Bottlenecks
Elasticsearch uses a document-replication mechanism that replicates full shards across nodes. This process was too slow for DoorDash’s rapid data growth, where menus, items, and store data constantly change.
Complex Relationships
DoorDash’s search required modeling intricate relationships:
Items belong to stores.
Stores exist in specific geographies.
Relationships between entities impact search results.
Elasticsearch wasn’t built to handle these relationships efficiently, requiring fragile workarounds.
Query Understanding and Ranking
Elasticsearch didn’t offer native support for query understanding or ranking logic. DoorDash needed advanced capabilities like:
Parsing user intent (e.g., “vegan pizza near me”).
Ranking results based on user preferences, reviews, and delivery speed.
DoorDash concluded that sticking with Elasticsearch would lead to ongoing scaling issues and subpar performance under heavy load.
OK, So What Are the Requirements? 🤔
To address these challenges, DoorDash needed a search engine that could:
1️⃣ Scale with Growth
Handle spikes in traffic and frequent updates without slowing down.
2️⃣ Model Complex Relationships
Natively support relationships like item-to-store and store-to-geo-location.
3️⃣ Enable Query Understanding
Parse and optimize user queries for better precision and ranking.
4️⃣ Isolate Multi-Tenant Workloads
Ensure one heavy traffic from one workload wouldn’t degrade performance for others.
5️⃣ Reduce Costs
Improve efficiency to control hardware and operational expenses.
🔍 What Is Apache Lucene?
At the heart of DoorDash’s solution is Apache Lucene, a search library known for its flexibility and performance. Here’s how it works:
1. Inverted Index
Lucene uses an inverted index, mapping each token (word) to the documents it appears in. This structure allows fast lookups, even with large datasets.
2. Tokenization and Stemming
Lucene breaks text into tokens (e.g., splitting “chocolate donut” into “chocolate” and “donut”) and normalizes them (e.g., “run” vs. “running”).
3. Segment-Based Indexing
Lucene splits indexes into immutable segments. New data is added as segments, making updates efficient without re-indexing everything.
4. Customizable Ranking
Lucene allows developers to implement custom ranking algorithms, such as BM25 or machine-learning-based models.
🏗️ Inside DoorDash’s Search Engine
DoorDash’s search engine architecture separates indexing and querying into distinct services.
1. Indexer
The indexer processes updates and creates index segments.
High-priority updates: Changes like menu updates are indexed immediately.
Bulk updates: Non-urgent updates are batched every six hours to reduce load.
AWS S3: Segments are stored in S3 for durability and distributed access.
2. Searcher
The searcher handles query traffic independently of indexing.
Scalable Replication: Searcher nodes scale dynamically to handle spikes.
Lucene-Powered Queries: Advanced filtering, geo-searching, and ranking.
3. Broker Service
The broker service orchestrates queries, ensuring results from multiple shards are merged seamlessly.
Fans out queries to relevant shards.
Handles query optimization and ranking logic.
Merges results for the final response.
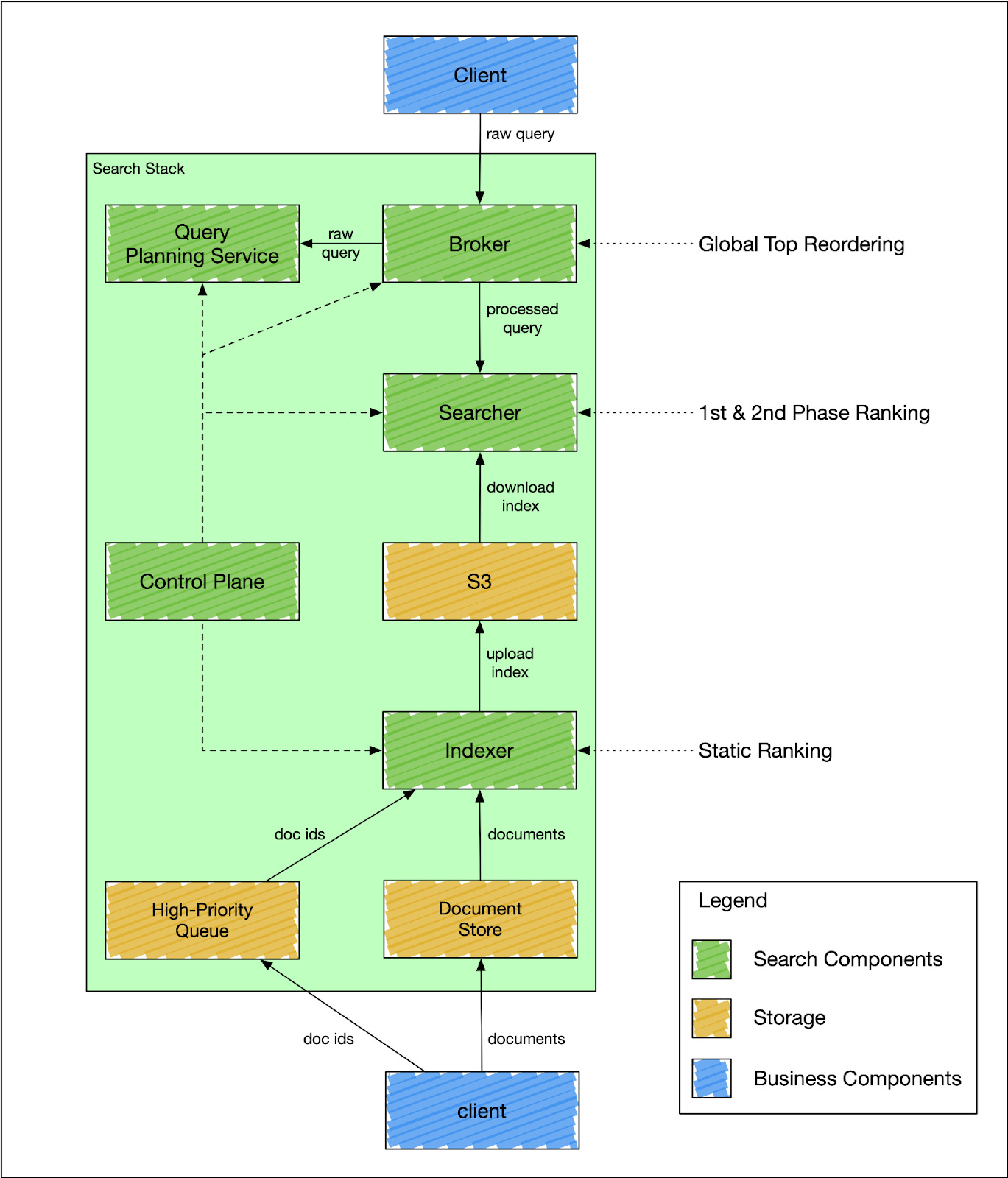
🌍 Multi-Tenant Architecture
To support multiple teams without interference, DoorDash implemented search stacks.
What Is a Search Stack?
Each stack is an isolated collection of services (indexer, searcher, broker) dedicated to a specific use case.
Tenant Isolation: Each search stack operates independently, handling its own index and queries. This ensures that traffic spikes or errors in one stack don’t impact others, thus avoiding any noisy neighbor issues. Resources are tracked per tenant, making it easy to manage usage and maintain accountability.
Custom Schemas: Teams can define their own index structures and ranking logic.
Control Plane
The control plane orchestrates deployments and schema changes. Updates roll out gradually, with old stacks remaining live until transitions are complete.
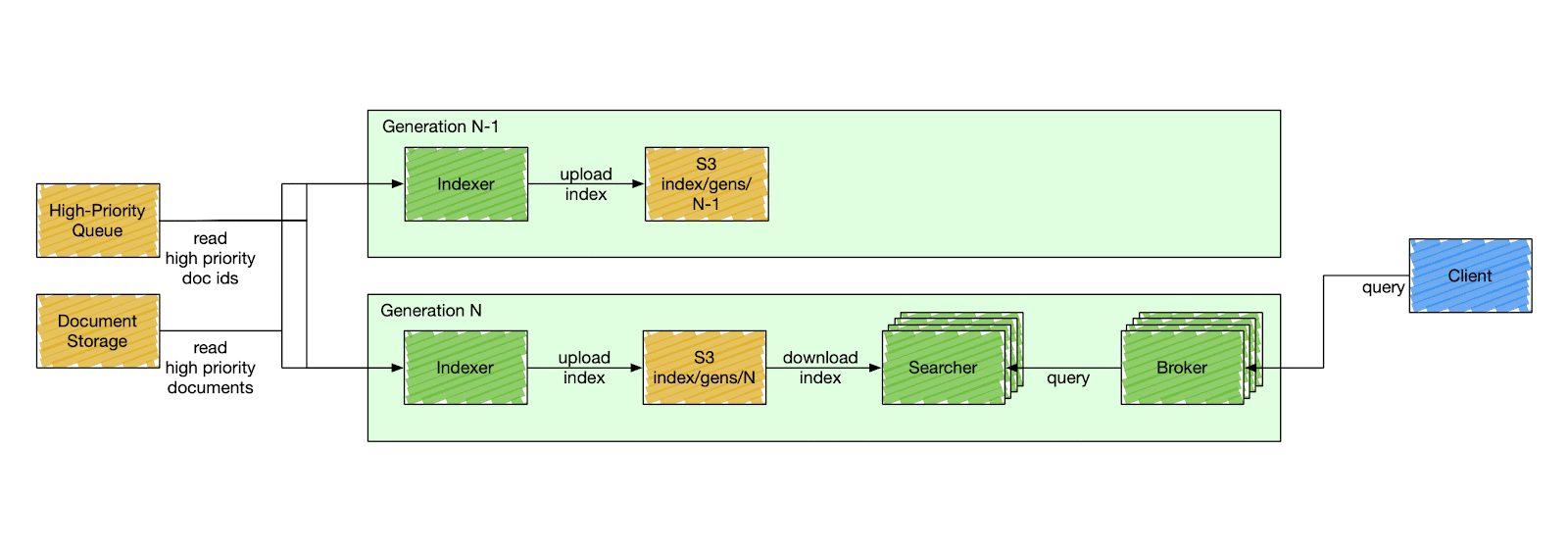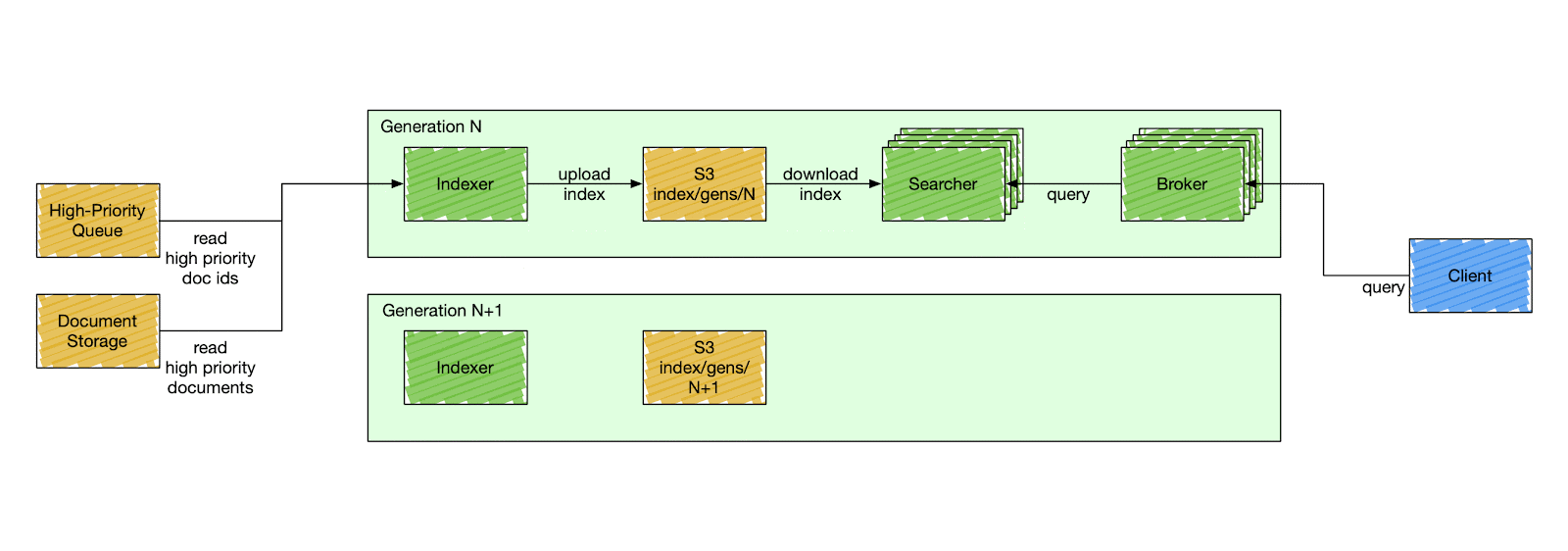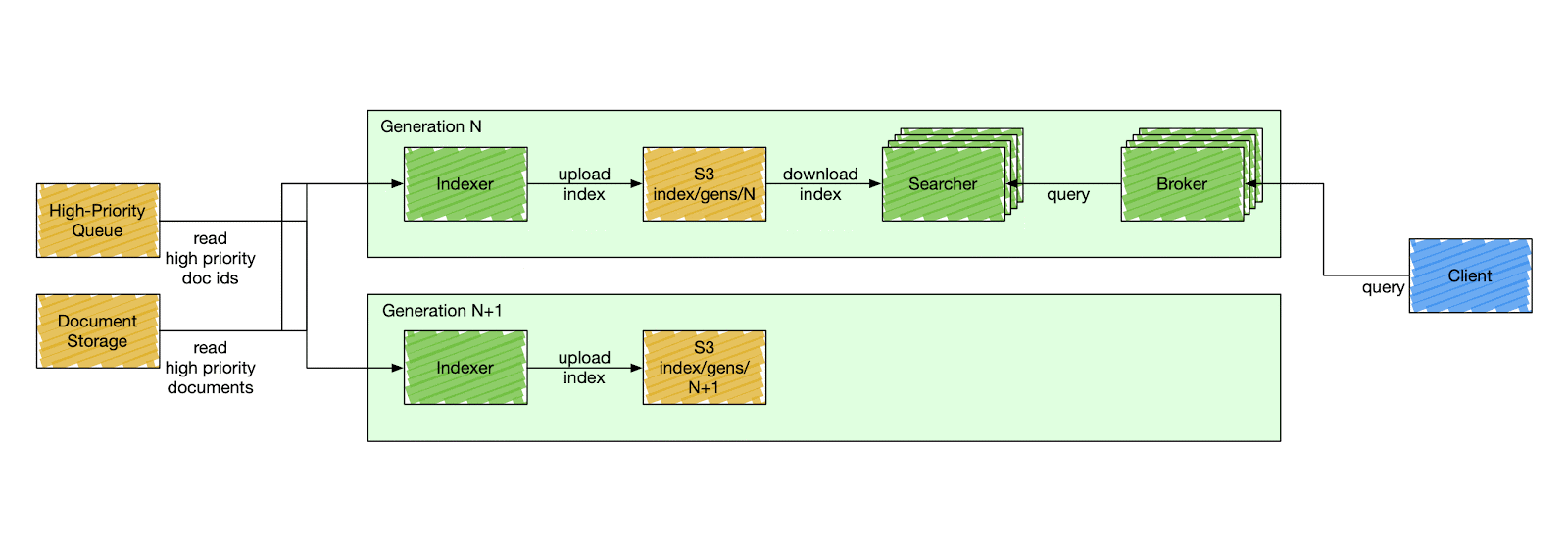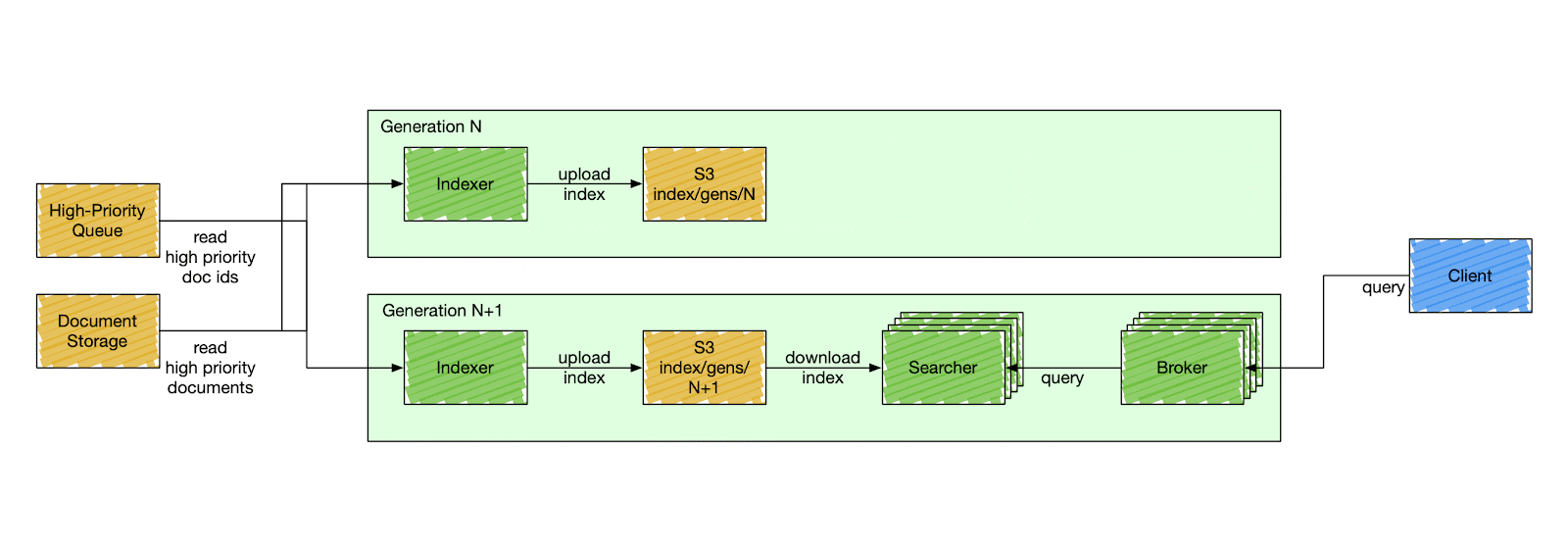
🛠️ How It’s Different from Elasticsearch
1️⃣ Fully Decoupled Indexing and Querying
Indexing and querying are completely separate, avoiding bottlenecks.
2️⃣ Segment-Based Replication
Segments are smaller and easier to replicate, reducing latency and cost.
3️⃣ Centralized Query Understanding
Query parsing and optimization are handled centrally, simplifying client integration.
4️⃣ Flexible Ranking with ML
Machine learning-based ranking tailors results to DoorDash’s business needs.
❗Doesn’t Elasticsearch Separate Indexing and Querying at all ???
Elasticsearch does separate indexing and querying at a high level, but there are important nuances that differentiate it from DoorDash's custom solution:
Shared Resource Pool:
In Elasticsearch, different node types can be dedicated to specific responsibilities, such as indexing (data or ingest nodes) and querying (coordinating nodes). However, these nodes still share the same underlying cluster resources. This means that heavy indexing loads can still impact query performance unless the cluster is carefully configured and resourced to handle both tasks simultaneously.
Impact on Query Latency:
Because indexing and querying share nodes, high indexing activity (e.g., bulk updates) can lead to increased query latency. DoorDash addressed this by completely separating these workloads into distinct services.
Index Refreshes:
Elasticsearch relies on a periodic refresh mechanism (default: 1 second) to make newly indexed documents available for search. This can introduce a delay for near-real-time queries. DoorDash’s approach, with its explicit high-priority and bulk update separation, allowed tighter control over when updates became available for querying.
Architectural Isolation:
Elasticsearch operates with a unified cluster design where indexing and querying occur on the same infrastructure. In DoorDash’s solution, indexing traffic and query traffic are processed by entirely separate services, ensuring that high indexing loads don’t degrade query performance.
In short, while Elasticsearch does logically separate the tasks of indexing and querying, DoorDash went a step further by physically isolating these workloads to achieve higher performance and scalability tailored to their specific use case.
🔔 Too Long; Did Read
DoorDash didn’t just fix their search problems—they built a scalable, high-performing engine tailored to their needs. For senior engineers, the lesson is clear: sometimes, building custom is the only way to keep growing.
Subscribe to Byte-Sized Design for more insights into system design and scaling strategies. 🚀
🔔Follow Us for More!
Want daily, byte-sized system design tips to level up your skills? Follow us on LinkedIn and Twitter for insights that make complex concepts simple and actionable!
💡 More Insights, Quiz & Official Link (Paid)
Query Understanding Pipeline
DoorDash’s query pipeline optimizes user searches to improve relevance:
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.