
When KV Falls: Cloudflare’s Two-Hour Outage
How a Single Storage Dependency Broke Access, WARP, AI, and More

TLDR
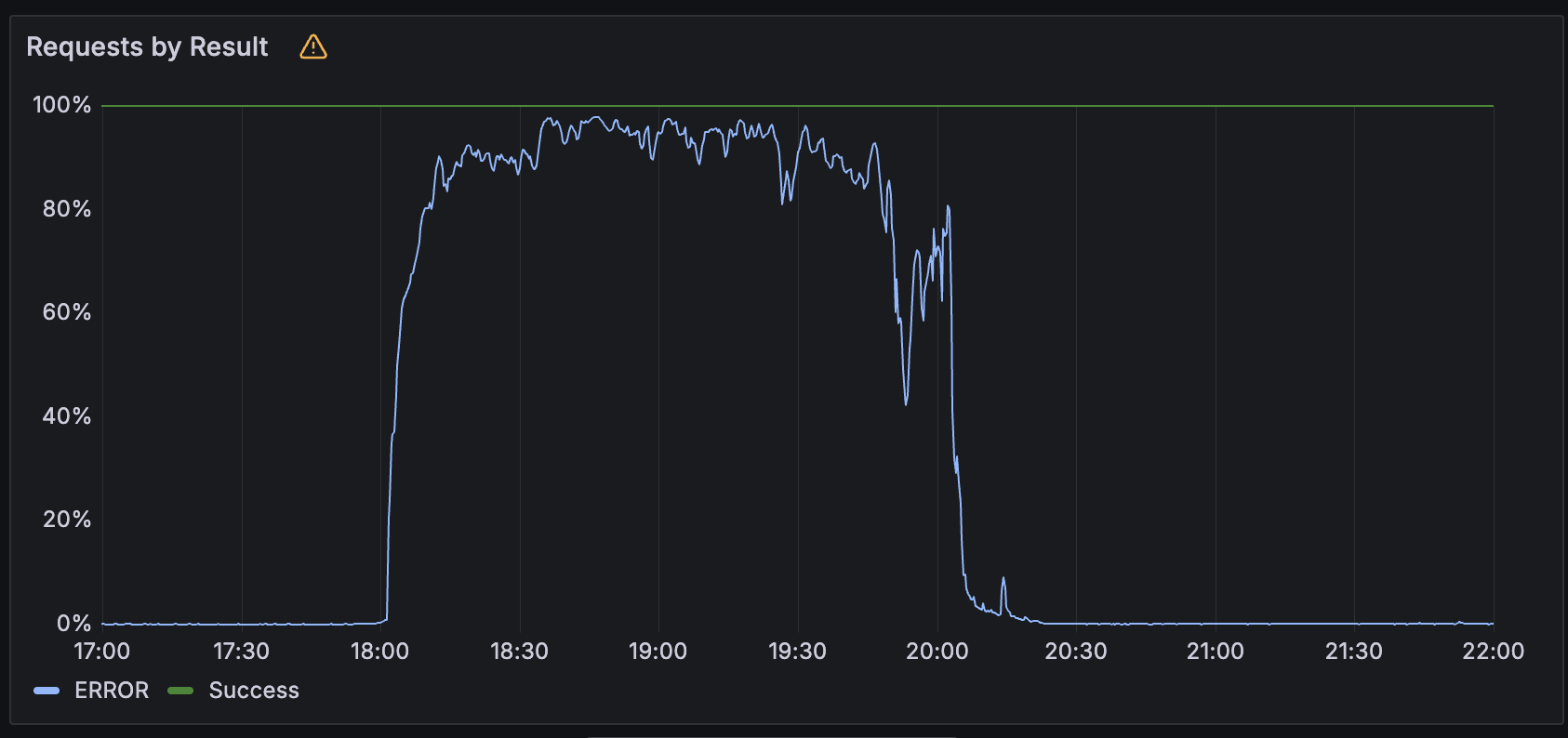
On June 12, 2025, Cloudflare experienced a 2 hour 28 minute outage affecting core products: Workers KV, Access, WARP, Gateway, Images, Stream, Workers AI, AutoRAG, and the Dashboard.
Root cause? Workers KV’s underlying third-party storage provider failed, cutting off cold reads and writes globally. KV powers identity, config, and asset delivery across Cloudflare’s stack. With no fallback, services dependent on KV failed closed, breaking everything from user logins to AI inference.
Below is what broke, why, how Cloudflare contained blast radius mid-incident, and key lessons for distributed system design.
Workers KV: The hidden backbone
What went wrong
Workers KV is designed as “coreless,” with each Cloudflare location operating independently.
But it relies on a central data store as source of truth to sync across locations.
The third-party storage provider (unnamed) suffered an outage, making KV’s cold reads/writes unavailable globally.
This resulted in:
✅ Hot cache hits survived (status 200 or 404).
❌ Cold reads and writes failed with 503/500 errors, affecting 90%+ of requests.
Cascading impacts: A domino effect
Because KV is woven into nearly every Cloudflare product, failures cascaded:
Access: 100% login failure for identity-based logins (SaaS, self-hosted, SSH command logs). SCIM syncs failed with 500 errors.
WARP: No new clients could connect. Existing sessions routed via Gateway failed policy evaluations.
Gateway: Identity-based DoH queries failed; proxy and TLS decryption inoperable.
Turnstile and Challenges: Siteverify API failed. Kill switches were activated to prevent user lockouts, but token reuse attacks were possible.
Workers AI: All inference requests failed.
AutoRAG: Unavailable due to Workers AI dependence.
Stream: Video playlists unreachable; Stream Live 100% down.
Realtime TURN/SFU: TURN near-total failure; SFU could not create new sessions.
Dashboard logins: Blocked due to Turnstile, Access, and KV failures.
Images & Pages: Batch uploads failed; Pages builds halted with 100% failure.
D1 & Durable Objects (SQLite-backed): Peaked at ~22% error rate.
Despite the widespread impact, Magic Transit, Magic WAN, DNS, cache, and proxy services remained operational.
Incident management: Scoping, triage, and partial mitigations
Timeline highlights
17:52 UTC – WARP team detects device registration failures.
18:05 – Access team triggers alerts for login errors.
18:06 – Incident priority upgraded to P1, later escalated to P0 by 18:21 as impacts cascade.
18:43 – Access team explores migration to alternative backing store.
19:09 – Gateway degrades gracefully by removing identity/device posture rules.
19:32 – Forced load shedding of identity and device posture requests.
20:23 – Recovery begins as third-party storage comes back online.
20:28 – Incident resolved.
Engineers coordinated fast-moving mitigation streams: rerouting critical config storage, disabling non-critical features, and prepping KV cutover to Cloudflare R2 in case the third-party outage persisted.
Key lessons: Designing for blast radius
✅ Avoid singular storage dependencies, especially third-party managed ones.
✅ Graceful degradation matters: Gateway shed rules safely; Access failed closed to maintain security.
✅ Cache is not a fallback when cold reads are required for authentication/config.
✅ Kill switches must account for security trade-offs (e.g. Turnstile token reuse risk).
✅ Incident response discipline – P0 escalation, service-by-service mitigations, and comms channels prevent chaos during multi-hour global outages.
What’s next
🔧 Migrating Workers KV to Cloudflare R2 to remove dependence on a single provider.
🔧 Product blast radius reductions, so future KV outages don’t cripple unrelated services.
🔧 Progressive namespace re-enablement tooling to avoid denial-of-service from mass cache repopulation post-recovery.
🔧 Architectural re-evaluation of cross-service critical path dependencies.
🧠 Best Practices & Mistakes
1. Distributed doesn’t mean decoupled
It’s tempting to call something “coreless” and believe you’re safe. Workers KV was designed to run in each Cloudflare location independently, but it still needed a central data store as the source of truth. When that went down, everything relying on cold reads broke.
👉 When the scale justifies it: If you’re operating a global service with millions of requests per second, double-check every “stateless” claim.
Ask: What’s the source of truth here, and can it fail? For smaller systems, central stores are often fine, but at Cloudflare scale, a single-provider store is a critical risk.
2. Fail closed vs. fail open isn’t academic
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.