


🏗️ How Quora Migrated a Decade of Redshift to Trino (and Lived to Tell the Tale)
Lessons in Migrating a Core Data System Without Breaking Everything

🚨 TL;DR
Over a decade, Redshift became tightly woven into Quora’s data systems, powering dashboards, A/B testing, and ad-hoc analytics. But as scale grew, so did pain: spiraling storage costs, constant firefighting, and architectural complexity.
In 2022, they committed to migrating everything to Trino. The journey involved auto-converting thousands of SQL queries, shadow-validating results at scale, optimizing joins manually, and ultimately cutting 50% of their costs.
This edition breaks down why Quora abandoned Redshift, how they pulled off the migration, and what you should watch out for when modernizing critical systems.
📖 What Will We Dive Into Today?
Why Redshift was great—until it wasn’t
The storage and maintenance traps at scale
How Quora auto-converted 2,000+ queries to Trino
How to Plan Migrations Without Meltdowns (Paid)
How to Rebuild Joins, Buckets, and Indexes for Speed (Paid)
How to Future-Proof Your Data Architecture (Paid)
🧱 Why Redshift Worked (At First)
When Quora started scaling, Redshift seemed perfect:
🔥 Fast small queries: Ad-hoc analysis without heavy tuning
⚡ Simple setup: Managed service, SQL native
📈 Powerful for OLAP: Dashboards, product metrics, A/B tests
✏️ Relational features: Easy updates/deletes compared to S3/Hive
But these early wins hid ticking time bombs.
💣 What Went Wrong
1. Complexity Explosion
Managing Redshift and Spark and S3/HDFS meant:
Constant data duplication
Different teams using different SQL dialects
Schema changes triggering cascading failures
Tooling and monitoring fragmentation
2. Storage Death Spiral
Using Redshift DS instances (compute + storage bundled) created an ugly trap:
Storage shortages despite unused compute
Only way to add storage? Buy more nodes (and waste money)
Constant "VACUUM" jobs needed to free space
Split-table strategies needed for long-term retention
3. Cost Overruns
Scaling Redshift required constant node additions, emergency provisioning, and manual maintenance—all of which drained engineering time and budget.
🚀 Why Trino?
Quora needed a query engine that could:
Read data straight from S3 Hive tables
Handle analytical SQL workloads
Be open-source, extensible, and self-hosted
Integrate smoothly into their Spark/S3 stack
Trino fit the bill. It was already in limited use—and it was fast, flexible, and free from storage lock-in.
🛠️ How They Migrated (Without Losing Their Minds)
🔍 Step 1: Full Query Observability
Custom Redshift query logging captured:
Full SQL text
Table dependencies
Query runtime
Call location (Python module + function)
No "unknown unknowns" left behind.
To learn more about observability read our previous edition “The Engineer’s Guide to Observability: Making Metrics, Logs, and Traces Work for You”.

📋 Step 2: Double-Write All Tables
Every Redshift table was mirrored to a Hive equivalent via automated copy jobs.
This guaranteed no missing data during the migration—and decoupled data prep from query rewriting.
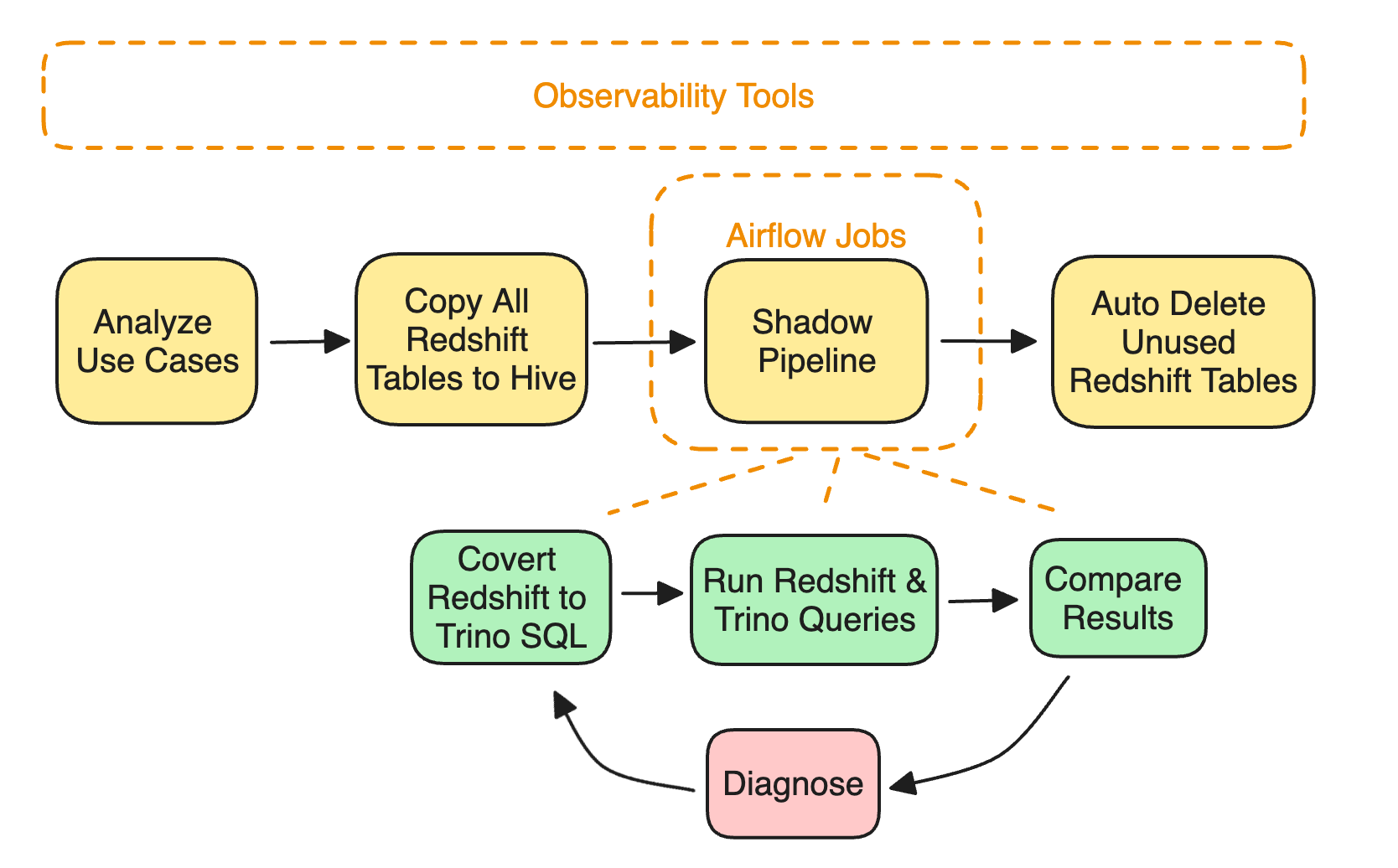
⚙️ Step 3: Automate SQL Conversion (Twice)
First attempt: Regex-based rewrites (DATEDIFF → DATE_DIFF, etc.)
Reality: Regex melted on complex queries (nested casts, lateral aliases).
Pivot: Adopted SQLGlot, an open-source SQL syntax tree converter:
Parsed full query trees
Handled deep rewrites safely
Added custom rules for quirks like Trino’s stricter type enforcement
🧪 Step 4: Shadow Pipelines for Validation
Every migrated query ran side-by-side with the original Redshift version.
Results were auto-compared, tolerating minor float rounding drift.
Alerts for any non-trivial data mismatches, triggering manual investigation.
We’ve talked about this in our previous edition “Modernizing Legacy Systems Without Breaking Production”. Give it a read!

⚡ What Surprised Them
1. Query Performance Cliff
Some migrated queries ran 10x slower in Trino—because of bad join planning.
Root Cause: No table statistics = bad cost-based optimization.
Fix:
Run
ANALYZEon big tables to generate Trino statsRewrite JOIN orders manually where needed
Bucket Hive tables and define
sorted_byindexes for faster access
2. Updates and Deletes Got Harder
Redshift = easy in-place table updates.
Trino on S3 = full partition rewrites required.
Result? Longer write times and higher downtime risk.
3. Autoscaling Was Mandatory
To hit their SLA for daily A/B tests, Quora had to triple Trino cluster size—temporarily.
They built Airflow triggers to pre-scale clusters before peak jobs, then shrink afterward.
Saving costs without missing deadlines.
🧠 What Quora Learned (And So Should You)
Multiple storage systems will kill your agility. Consolidate early.
Storage/computation coupling (like Redshift DS nodes) is a silent budget killer.
Regex will always fail at serious query rewriting. Use syntax trees.
Auto-validation at scale saves you from silent data corruption.
Table stats are life or death for modern query optimizers.
Assume in-place updates may not exist in your future system. Design accordingly.
🧠 How to Plan Migrations Without Meltdowns
Most migrations fail because the transition wasn't survivable.
Here’s how to design a migration process that doesn’t blow up your team or your customers.
Keep reading with a 7-day free trial
Subscribe to Byte-Sized Design to keep reading this post and get 7 days of free access to the full post archives.