
How Uber Killed Hours-Old Data (And Why Your Batch Jobs Are a Liability)
What they found when they finally did the math on stale data.

TLDR
Hours-old data. Petabyte scale. Thousands of engineers making decisions on stale numbers.
Uber’s data lake powers Delivery, Mobility, Finance, Marketing Analytics, and Machine Learning for a company with hundreds of millions of users. For years, the ingestion layer ran on Spark batch jobs. Data arrived in the lake hours late. Sometimes a full day late.
That was fine when the business moved slowly. It stopped being fine when data freshness became a competitive bottleneck—when model iteration speed, real-time experimentation, and operational analytics demanded minutes, not hours.
So they rebuilt ingestion from scratch on Apache Flink. The result: freshness dropped from hours to minutes, compute costs dropped 25%, and the system now handles petabyte-scale streaming across thousands of datasets.
This is IngestionNext. And the problems they had to solve to get there are exactly the kind of problems most data teams quietly ignore until they can’t anymore.
The Dirty Secret About Batch Ingestion
Here’s the thing nobody wants to say out loud: batch jobs are slow by design, and most teams have just accepted that as the cost of doing business.
You run a Spark job every hour. Maybe every 30 minutes if you’re ambitious. The job spins up, reads from Kafka or a transactional database, transforms the data, writes it to the lake. Then it tears down. An hour later, it does it all again.
At small scale this is totally fine. Predictable. Easy to debug. The operational overhead is low.
At Uber’s scale, hundreds of petabytes, thousands of datasets—those batch jobs were burning hundreds of thousands of CPU cores every day. Not because the work required that many cores. Because that’s how batch scheduling works. You provision for the peak, the peak is infrequent, and everything in between is wasted capacity.
And even if you ignore the cost problem, there’s no fixing the freshness problem. Batch is batch. If your job runs every hour, your data is up to an hour old. Period.
For model training, that’s a delay in experiment velocity. For fraud detection, that’s a window where bad actors operate undetected. For marketplace analytics, that’s a lag between what happened and when anyone can respond to it.
Uber looked at this and decided hours-old data was no longer acceptable. They needed minutes. That meant streaming.
If you want to see how Uber’s data lake got to 350PB in the first place, and the replication problems that scale created, read Inside Uber’s 350PB Data Lake: The Distcp Rewrite That 5x’d Performance.
Inside Uber’s 350PB Data Lake: The Distcp Rewrite That 5x’d Performance
·TLDR 250 TB to 1 PB per day. One quarter. Daily replication jobs jumped from 10,000 to 374,000. Uber’s data lake hit 350 PB and their copy tool couldn’t keep up. The P100 SLA of 4 hours became a joke.…

Why Flink, Not Just “More Spark”
The obvious question: why not just run Spark Structured Streaming? It exists. It integrates with Kafka. Half the data ecosystem already knows how to use it.
Because Spark Structured Streaming still thinks in micro-batches. It’s better than full batch scheduling, but it’s not true streaming. You’re still dealing with the same fundamental model: accumulate records, process a chunk, commit.
Flink is a different mental model. It processes records as they arrive. Checkpoints are asynchronous, not tied to batch intervals. The state management is first-class. For continuous ingestion at this scale, Flink’s execution model is a better fit.
Uber already had Flink infrastructure. The ecosystem supported it. That made the decision easier, but the architecture challenges were anything but easy.
Pinterest went through a similar reckoning with Spark at scale, rebuilding their entire Hadoop-based platform into a container-native Spark system. Worth reading alongside this one: How Pinterest Runs Spark at Scale with Moka.
⚡ How Pinterest Runs Spark at Scale with Moka
·Pinterest’s old data platform was called Monarch. It ran on Hadoop. It powered everything from ad analytics to recommendation training.

The Architecture
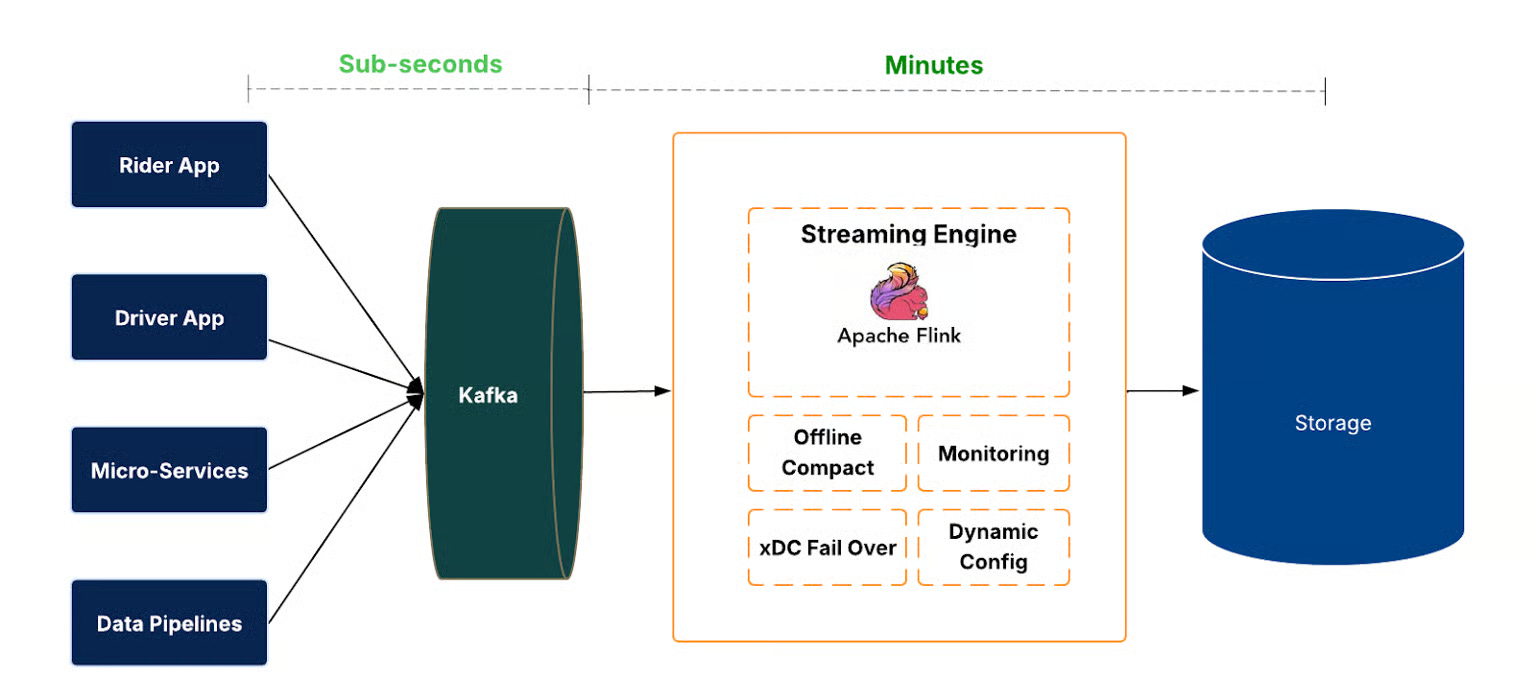
Events arrive in Kafka. Flink jobs consume them continuously and write to the data lake in Hudi format.
Hudi is doing serious work here. It provides transactional commits, rollback support, and time travel queries on top of what would otherwise be raw Parquet files on object storage. When a Flink job fails mid-write, Hudi rolls back the uncommitted data. When someone wants to query data as of a specific timestamp, Hudi handles it.
Above the data plane sits a control plane that manages the job lifecycle across thousands of datasets. Create, deploy, restart, stop, delete—all automated. Configuration changes propagate without manual intervention. Health checks run continuously. This isn’t glamorous infrastructure work, but at Uber’s scale, “we have 4,000 ingestion jobs” means operations without a control plane is a full-time fire drill.
There’s also regional failover. If a region goes dark, ingestion jobs reroute or fall back to batch mode. No data loss. No manual intervention required.
The architecture isn’t surprising. The interesting parts are the problems that showed up once it was running.
